http://pc.watch.impress.co.jp/docs/2007/1128/rambus.htm
Rambus、1TB/secのメモリバンド幅を実現する構想
http://pc.watch.impress.co.jp/docs/2007/1130/rdf1.htm
RambusはXDRの4倍速でTB級伝送を目指す
關鍵字是「Terabyte Bandwidth Initiative」「32X Data Rate」、「FlexLink C/A(Command/Address)」、「FDMA(Fully Differential Memory Architecture)」。
嘴巴講起來非常嚇人,1TB/s聽起來簡直就是天文數字;不過如果把XDR2考慮進去的話就沒那麼誇張了。
這回的設計是16個4byte寬、共計512bit的介面跑16Gbps,32x Data Rate(500MHz clock x 32)的設計;而XDR2是32bit per channel、8Gbps、16x Data Rate的設計,也就是傳輸時脈加倍與多工倍增的方式,上達到XDR2約兩倍的傳輸性能。
嚴格說來,XDR2是XDR的兩倍(4Gbps vs 8Gbps),所以TBI是XDR2的兩倍、XDR的四倍,基本上只是正常進化;使用的傳輸是FDMA全差動傳輸記憶體結構,所以連command和address都改為差動傳輸的這個技術稱為FlexLink C/A,和本來的介面合稱為FDMA。
此外,因為全部serial化的關係,晶片的腳位數可以再減少,使得單顆的介面從16bit變成32bit(與GDDR4同),單顆的頻寬實質上是四倍。也當然都有FlexPhase非等長布線能力….
PCB層數則為信號線兩層、電源一層、接地一層,一共四層,這也與過去的XDR相同。
此外,XDR目前採用的產品實作是CELL的64bit、參考設計到128bit(共480腳),而XDR2參考設計實作到256bit、所以XDR3衝512bit似乎是理所當然….
而且TBI與XDR2一樣都是500MHz運作,很多技術也都是沿用XDR/XDR2改良而來,也就是可說是順理成章的的進化。

值得注意的是die size數字:I/O的規模會決定晶片長寬的最小值。
當然這是512bit TBI的狀況….同等頻寬的話只會和DDR系統的差距更大。
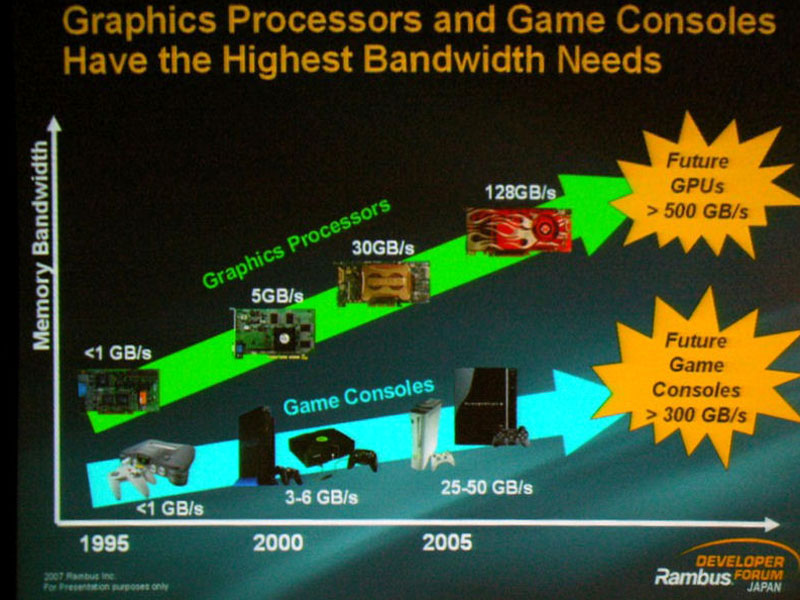
未來的GPU的總頻寬會衝>500GB/s應該是很肯定的,不過console真的會衝>300GB/s嗎?
不是因為Wii 然後性能永遠爬不起來嗎?XD
總之,TBI的預計推出時間是2011年,從時間看起來真的很像是配合新CELL與PS4…. XD
畢竟從各種設計因素來看,最需要TBI的產品顯然是CELL:
在EIB搭配設計擴充的前提下,同樣使用4個晶片的狀況下,TBI提供相對於XDR八倍大的頻寬(25.6GB/s vs 64GB/s x 4 = 256GB/s),幾乎正好滿足八個SPE全速讀寫的頻寬需求。
所以變成16個晶片,正好滿足預計擴充到32個SPE的新CELL;而且222mm^2左右的周圍需求也正好與目前的CELL、以及未來預測的CELL-32SPE版大小相同….
個人認為這形同量身訂作。XD
不過還有一個候選者是Intel Larrabee,因為最近有傳出RAMBUS和Intel在洽談的狀況。
最後是各GPU廠商:RAMBUS先前曾經放話有主力GPU廠商在和他們洽談。
不過ATI曾經有大頭講過他們堅持開放標準,所以應該只剩NVIDIA有機會;但是NVIDIA又都自己設計DRAM controller,他們願意用整套的RAMBUS solution嗎?這也是疑問。
不知道NV与AMD看了做何感想?RAMBUS与各GPU厂商洽谈的如何?NV与AMD就看谁先吃螃蟹
GPU还要多久才能冲到500GB/s?5年还是10年?
>何時衝到500GB/s
以RAMBUS的說法,他們認為每五年會快十倍,比方說2005年的PS2是3.2GB/s、XBOX是6.4GB/s;PS3是50GB/s、360是22.4GB/s;GPU則是以256bit的FX5900、到512bit的2900XT為例,從30GB/s成長到128GB/s的算法….
所以他們是預計要在2010~2011年,GPU需求線性提升,達到500GB/s的時候,提出這個1TB/s的記憶體系統。
包含在标题里的TBI是什么意思?
NEXT XDR(TBI)的延迟有多高?如果太高了是不是需要大容量且高速的CACHE来辅佐以降低延迟呢?next XDR(TBI)各方面的性能参数是否能好过GDDR5/6?
512bit TBI需要多层PCB啊?用多少颗粒才能达成512bit TBI?
xdr3技术是很先进,就看有没有人(GPU厂家)用了
TBI = Terabyte Bandwidth Initiative
XDR2與TBI的PCB需求相同,都是四層、兩層信號一層電源一層接地;達到1TB/s是16個顆粒、32bit x16個共 512bit。
話說這些問題文章內都有寫啊….XD
—-
延遲的話,由於它仍然有Micro-threading的關係,時脈提高的同時也倍增了threading,所以應該可以維持與XDR2同程度的延遲;而這大概是GDDR3-800MHz的50(寫入)與80%(讀取),所以GPU應該不需要大幅度的架構改變(維持現有的設計)就可以應付這個延遲。
來源:
http://stor-age.zdnet.com.cn/…/0808/398137.shtml
mydrivers那边的消息说TBI运行在32X时数据传输率为64Gbps
host clock 是 500MHz的狀況下,為什麼32x會變成64Gbps?
16Gbps or 16Gtps per pin才對啊?
mydrivers那應該是64GB/s 單晶片的筆誤吧?
這有原文可以校對:
http://pc.watch.impress.co.jp/…7/1130/rdf104.jpg
关键在于TBI的DRAM controller DIE SIZE有多大
是啊,MC的大小是個問題,以先前CELL和同製程的Opteron來比較的話,感覺上64bit的XDR就已經比128bit的DDR2 controller大很多…. 🙂
64bit XDR就已经比128bit DDR2 controller大很多了,
那么大的controller GPU能塞得进去吗?就算能塞得进去想必耗费的电晶体也不少吧,这样算下来还能留多少电晶体给GPU的运算单元呢?另外消耗的电力肯定不会少,那么散热也是个大问题NV如何解决?
以 64bit Xdr controller 來說跟 PCI-E I/O 相比所佔的電晶體相去不遠,另外相較於現在 GPU 做到 700M 的規模來說更是小到不行,耗電來說類似的單元吃電多半都不會太大。
從這張發熱圖來看
http://pc.watch.impress.co.jp/…08/kaigaip051.jpg
真正吃電的還是在運算單元上面
另外一點是如果要拿 XDR 64bit 的 controller 來跟 DDR series 做比較的話以 128bit DDR3 做對比會是比較好的。
以這方面來說 MC 的大小影響應該是不會比記憶體價格或是有效頻寬及布線成本等東西要來的大的。
> 64bit XDR就已经比128bit DDR2 controller大很多了,那么大的controller GPU能塞得进去吗?
當然塞得進去啊,TBI基本上只影響最小晶圓大小而已,而且那是512bit時的狀況。
> 就算能塞得进去想必耗费的电晶体也不少吧,这样算下来还能留多少电晶体给GPU的运算单元呢?
還是能留不少啊,就算是對Opteron來說,DDR控制器其實也不是占那麼大的規模;而且頻寬變成同時期DDR系列的2.5倍(同時期NGM Diff最大頻寬是6.4Gbps),技術本身是很有吸引力的,重點是XDR系的記憶體產量。
> 另外消耗的电力肯定不会少,那么散热也是个大问题NV如何解决?
我覺得散熱本身不是問題,MC的phy耗電量在GPU裡面比例並不大,雖然大了好幾倍,但是成長後仍然很可能在10%以下;而且上面說了,有成長後的頻寬當交換。
—-
我覺得真正的問題是:
NV比較習慣自己處理memory controller,他們願意用這種空降的solution嗎?
而且shader的比重日益提升的狀況下,GPU的記憶體系統以超越整個記憶體標準進步速度的狀況已不常見,GPU業界真的有必要使用TBI?其實是值得懷疑的。
以 64bit Xdr controller 來說跟 PCI-E I/O 相比所佔的電晶體相去不遠,另外相較於現在 GPU 做到 700M 的規模來說更是小到不行
你总不至于让高端GPU只装配64bit xdr controller吧?
现在的64bit xdr controller都已经比128bit DDR controller大那么多了,GPU要是上512bit TBI,controller的规模肯定不会小于512bit ddr controller,GPU厂商怎么解决这个问题?
比 512bit ddr controller 大然後呢? 比 512bit ddr controller 大就會有問題嗎? 真正的問題應該是大多少而在使用到該 controller 的 GPU 真的會覺得他大嗎? 以 TBI 要求為主的 GPU 本身會有多大? 700M? 還是數倍於這個數字,要說 controller 會造成上述的問題我想不如先擔心 GPU 本身在超高電晶體的情況下能不能解決這些問題,同樣的一點是 DDR 要做到跟 xdr 同等級的情況所要付出的東西是否會比較少,如果說他們真要用到 TBI,所要考量的主要問題並不會是 controller 是否較大而是記憶體價格是否過高,中低階產品線是否能通用之類的。
我想使用TBI的障礙應該還是RAMBUS系的產品在市場上的供貨能力….和晶片上的實作成本關係不大。
比方說很多人沒注意、不過XDR2系的Micro-Threading嚴格來說效果已經等於MC的前端crossbar了,雖然不清楚實際性能如何,但是有機會讓GPU內部的crossbar可以省略,光這個就可以省掉不少電晶體。
畢竟Crossbar和ringbus相比,一個是平方比例一個是線性比例規模,而且crossbar本身也是個高發熱量來源….而且當GPU規模在幾年後線性成長到現在的四五倍的時候,crossbar所”貢獻”的發熱量必然會更驚人。
(順道一提的是,NVIDIA原來的roadmap上,對1TB/s記憶體頻寬的預想是2015年前後)
但是就像先前說的,採用RAMBUS產品線,很可能代表許多自行設計的東西得放棄,這很可能與產品的optimize能力有很大的關係,NVIDIA願意嗎?
還有這與RAMBUS的IP使用規範、實作設計方向也有關….最有趣的是RAMBUS常常說他們的產品適合GPU等大頻寬需求產品,但是卻沒有GPU使用過,GPU和CPU的存取行為相差很大,就算CELL的行為很像GPU,你放心使用嗎?;加上前面的產品供貨能力問題,風險成本相比之下是改善還是惡化?
我相信這評估起來還蠻傷腦筋的。所以,某種意味上RAMBUS除了embedded system之外很難有斬獲的原因也在此了。
這部分還要看 DDR 方面究竟能不能繼續走下去,JEDEC 有比 Rambus 高明嗎? 或許我們能從 FB-DIMM 發展上面看出一點端倪(笑),另外一方面來說 DDR 雖說仍朝著超高頻發展問題是他所面臨到的 latency 日漸高漲跟有效頻寬比例日益低落也是不爭的事實,繼續往上面走時 DDR 能否有效的伴隨運算能力一同成長其實還是有待討論的,只不過從另外一個方面來說 PS3 上的 RSX 用的還是 GDDR3 我想不難看出採用 XDR 除了頻寬外還有不少其他的考量在裡面。
以 RAMBUS 來說現在要做的主要還是拉攏他們的大客戶 SCEI 以及宣示他們的新產品(IP),然後繼續收他們的權利金吧……..
现在就看RAMBUS有没有这个诚意把自家的DRAM controller交付给NVIDIA,让其自行设计
> 现在就看RAMBUS有没有这个诚意把自家的DRAM controller交付给NVIDIA,让其自行设计
講成交付好像很怪,這是IP授權的時候的使用協定的規定內容問題吧?能不能對IP本身做修改、比方說:如果提供的功能不足的話,使用的公司能不能去補強它,來滿足自己的需求。
就像NVIDIA授權RSX給SONY的時候,有規定SONY有權利可以對RSX做修改之類的,這包含配合自己產品的製程變更計畫,來變更它的一些設計;以業界慣例來說,這些東西應該都可以談啦。
我的意思就是NVIDIA能不能推翻RAMBUS先前的DRAM controller设计规范,自己重新设计一个optimize的TBI DRAM controller,当然这个前提是RAMBUS同意NVIDIA单干
> 我的意思就是NVIDIA能不能推翻RAMBUS先前的DRAM controller设计规范,自己重新设计一个optimize的TBI DRAM controller,当然这个前提是RAMBUS同意NVIDIA单干
完全從底層開始做….?要多底層?你PHY一定還是要用RAMBUS的原始設計啊,因為我想NVIDIA在這段是完全不能和RAMBUS比的,剩下裡面的controller部分應該很多都可以改、要打掉從頭做也可以,因為ROP的行為和controller關係都很深,只要你可以滿足time to market的要求…. 不過我覺得這似乎扯太遠了,TBI還不知道生不生得出來呢,面世應該不難,但是序列化的C/A規格全部做好之後,可能就是漫長的調升階段了。
總之TBI採用與否,我覺得只和JEDEC規格的記憶體必然的負面因素有關就是了。
达成1TB/S的带宽要动用到16颗显存,16颗会给布线带来很大的困难,目前的PCB极限是12颗,类似8800U X2900只具有象征意义
http://pc.watch.impress.co.jp/…7/1130/rdf108.jpg
怎麼會把 DDR 的佈線問題直接拿到 XDR 的情況下來討論呢…….
比 512bit ddr controller 大然後呢? 比 512bit ddr controller 大就會有問題嗎?
大当然会有问题,这会挤压到GPU里的其他部分所占用到的晶体,还有多少晶体能留给GPU本身呢?
RAMBUS免费提供PHY给NVIDIA,NVIDIA自己对DRAM controller在做一些深入的修改就可以最佳化了
> 大当然会有问题,这会挤压到GPU里的其他部分所占用到的晶体,还有多少晶体能留给GPU本身呢?
我想記憶體控制器對現在的GPU而言應該是皮毛的程度,更別提TBI發布時可能的GPU規模。
拿一個蠻微妙的數字做為參考,NV30/35的時代,從128bit擴展到256bit下,包含整個GPU的內部匯流排變更、FX12改為FP16 ALU、UltraShadow 與IntelliSample HCT等等總合所有的修改在內,電晶體數量增加的數字是從NV30的125M增加到NV35的130M,也就是說粗略估計下,記憶體控制器的膨脹對整個規模的影響其實是小於5%的。
對現在的G92而言,256bit GDDR3 MC實質上占的比率,應該是1~2%以下的範圍,一口氣增加到四五倍的大小,可能占的總規模比率也只是5%以下,而對2010年時代的GPU應該會保持目前的比率。
但是TBI的採用對記憶體系統的性能與對PCB layout困難度的改善,以及採用後的風險成本,我想這個評價範圍是NVIDIA的設計與經營者去傷腦筋就好啦….
以我的意見,TBI稱得上合算的範圍。
http://www.rambus.com/…releases/2007/071217.html