8/12才要上場的Siggraph08,但是因為Intel 提早把論文公布,所以可以提早看到performance。
http://softwarecommunity.intel.com/UserFiles/en-us/File/larrabee_manycore.pdf

Intel 的算法大概是說,為了達成60fps (或者說每frame在15ms內計算出來)所需要的核心數量。
所以從這個就可以反推,只要有上面明示最大的core數量,那麼min fps就至少是60。
GOW是約24個1GHz core就可以達到1600×1200 noAA 60fps…. 而以很久以前HardOCP的測試來說,8800GTX大約是min 44fps。
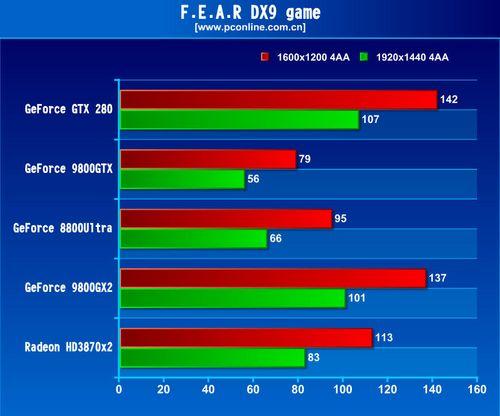
FEAR的話也很可怕,25個core可以達到4xAA最低60fps的關係,和大陸某些網站的測試比較的話GTX280大概是107FPS。

然後由於Intel宣稱只要追加核心,性能幾乎是線性成長。
所以如果實際推出的Larrabee產品是32core or 64core、2GHz的話,性能就會分別是上述的2.5倍或5倍了。
{kind=link}
所以”光是在GOW這款遊戲上”,Larrabee可以期望在和GT200差不多的die size上、用Intel的45nm製程放上64個小型core、可能超過2500M電晶體(相當於六個core2 duo的規模)、並且以單晶片發揮GTX280 SLI以上的性能。
[EDIT]:由於記錯core2 duo 65nm的規模,所以上述的推論數字要整個作廢;65nm Core2Duo的核心面積是143mm^2、電晶體是291M、核心本身(+32KB L1)是19M。
畢竟其實原文可能指的的是143mm^2的die size,架構不同數字差一大截的可能性更高…. 而如果以143mm^2為準的話,六倍再轉45nm會變成411mm^2前後。
而且斤斤計較的Intel做這麼大的可能性很低的關係,實際上32core 200~250mm^2前後比較適當。
—-
乍看之下Larrabee真的很有競爭力呢w
當然這樣估算實在是很草率,因為也不知道各自的記憶體頻寬是多少…._A_
(比方說,Intel先前就有”Core2Duo的模擬測試上假設核心有無限大的記憶體頻寬”)
這次Intel在Siggraph08的發表基本上也是個行銷,因為大部分的細節都不說,只說”預期性能”,也算是和當年PS2/PS3的”空氣主機”策略如出一轍就是了。
事實上這篇論文不只測這三款遊戲,但是卻只有這三款遊戲有放一些數據,可以想見這個數據應該是比較有可看性的才會被挑出來。
反過來說,如果和Core2duo同大小的狀況下可以放10個core,那麼至少就是core2duo 65nm的三倍或是六倍大的晶片了。
即使在45nm下會改善一些,core2duo 45nm的發熱量也是50w左右,那難怪Larrabee會被預估有300w的TDP…. XD
而且考慮Core2Quad可以賣到的價錢(光是Q6600都可以賣到五千台幣),相較之下Larrabee真是個賠錢貨….
我比較想看Crysis要達到60fps會需要幾個Core呢XD
所以說他們量幾十個遊戲不如一個Crysis砸下去….XD
所以說他們量幾十個遊戲不如一個Crysis砸下去….XD
2500M 比起 Cell 算是 10 倍大了,即使是下一代的 cell 應該也只會做到 5~6 倍大吧! 從另一方面來說如果能有 10 倍的運算量,性能會到 2.5T,以這數字來說沒有 ROP 等單元的確也是沒關係就是。
不過是否有這麼理想就還要再觀察了…
2500M 比起 Cell 算是 10 倍大了,即使是下一代的 cell 應該也只會做到 5~6 倍大吧! 從另一方面來說如果能有 10 倍的運算量,性能會到 2.5T,以這數字來說沒有 ROP 等單元的確也是沒關係就是。
不過是否有這麼理想就還要再觀察了…
以帳面來說,CELL放大到十倍大的話會變成有2.5TFLOPS的規模沒錯,但是64core 2GHz的Larrabee帳面上可能會有4TFLOPS的運算量,所以128bit和512bit還是有點落差。XD
此外,Larrabee有些graphic專用的指令,包含ROP用途相關的指令,而且這些指令的輸出可能會超過用簡單指令慢慢拼的性能,所以這邊差距會更大一點。
以帳面來說,CELL放大到十倍大的話會變成有2.5TFLOPS的規模沒錯,但是64core 2GHz的Larrabee帳面上可能會有4TFLOPS的運算量,所以128bit和512bit還是有點落差。XD
此外,Larrabee有些graphic專用的指令,包含ROP用途相關的指令,而且這些指令的輸出可能會超過用簡單指令慢慢拼的性能,所以這邊差距會更大一點。
intel只敢放數據,不敢放截圖
可見打高空的成分居多
如果說只要加核心數
不用管軟體怎麼寫,
就可以讓效能倍增
那可能嗎?
我覺得比較像打嘴炮!
intel只敢放數據,不敢放截圖
可見打高空的成分居多
如果說只要加核心數
不用管軟體怎麼寫,
就可以讓效能倍增
那可能嗎?
我覺得比較像打嘴炮!
話說我搞錯不少東西:410M是45nm Core2Duo(walfdale)的數字,L2有6MB,(4MB L2)65nm的core 2 duo的電晶體是291M、而1個core本身只有約19M。
如果Larrabee的core真的只有一般coreMA的1/5,那可是比CELL的SPE (扣掉LS約7M,總和約20M)還小,可能是因為SPE可以運作的最高頻率高得多。
——
to wei:
如果真的放出可以動的demo,那真的就死定了吧XD
當然上面說了,性能要能線性放大顯然記憶體頻寬會跟著提高,但Larrabee的記憶體頻寬需求的部份似乎是被忽略了。
話說我搞錯不少東西:410M是45nm Core2Duo(walfdale)的數字,L2有6MB,(4MB L2)65nm的core 2 duo的電晶體是291M、而1個core本身只有約19M。
如果Larrabee的core真的只有一般coreMA的1/5,那可是比CELL的SPE (扣掉LS約7M,總和約20M)還小,可能是因為SPE可以運作的最高頻率高得多。
——
to wei:
如果真的放出可以動的demo,那真的就死定了吧XD
當然上面說了,性能要能線性放大顯然記憶體頻寬會跟著提高,但Larrabee的記憶體頻寬需求的部份似乎是被忽略了。
問題是 64core 45nm 能跑到 2Ghz 嗎? nVidia 的
GTX 280 1.4B 65nm 是跑 1.3GHz,2.5B 45nm 要
直上到 2GHz 問題似乎還不小
SPE 畢竟不是單純的 vector unit,Larrabee 可以
把指令大量簡化,但 SPE 最少要把 Altivec 的東西
全吃下來,情況自然有些不同,當然應用的層級也不同
就是。
SPE 能跑高頻應該跟是否比 Larrabee 的單元要大無關
吧! 一般來說單元做的越大越耗電相對的不利高頻運作
問題是 64core 45nm 能跑到 2Ghz 嗎? nVidia 的
GTX 280 1.4B 65nm 是跑 1.3GHz,2.5B 45nm 要
直上到 2GHz 問題似乎還不小
SPE 畢竟不是單純的 vector unit,Larrabee 可以
把指令大量簡化,但 SPE 最少要把 Altivec 的東西
全吃下來,情況自然有些不同,當然應用的層級也不同
就是。
SPE 能跑高頻應該跟是否比 Larrabee 的單元要大無關
吧! 一般來說單元做的越大越耗電相對的不利高頻運作
>>Larrabee可以期望在和GT200差不多的die size上、用Intel的45nm製程…….只要追加核心,性能幾乎是線性成長。
其實gpu本來就是這樣的線性成長特性.
問題是GT200是啥製程?65 nm
仔細想想就知道Larrabee這價構
除了相容於x86外沒有多少競爭力….
如果直接把GT200用45nm去量產恐怕更有競爭力?
未來的架構更好的製程做出比美目前的GPU的效能??
這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
也許Larrabee它跑gpgpu會勝過gpu.
但在繪圖領域,目前已經是用數百cycle的pipeline和
數百上千的THREAD去吸收DRAM的latency,
未來的規模只會更龐大.
Larrabee架構上就沒辦法做到這麼側底.
恐怕又是要求用程式技巧避開問題.
很難~
用不同製程比DIE SIZE有取巧的感覺…
等他真的量產恐怕gpu已經又增強幾倍.
畢竟GPU 6~9月就改朝換代’,cpu卻要幾年.
當年cell也是認為可以在繪圖上大顯身手,
2002年當年看起來dx8(SHADER1.0)甚至未來
GEFORCEFX也不怎麼樣….但是當CELL大展身手時
卻已經是G80的時代了.
CPU架構有很多先天包縛在,ISA要用X86恐怕限制更大.
GPU是當時主流技術量身定做的硬體.
很多部份是不可程式化的,Larrabee的好處應該是
許多功能是用軟體做,沒支援的功能可以靠軟體追加.
但效能就….
>>Larrabee可以期望在和GT200差不多的die size上、用Intel的45nm製程…….只要追加核心,性能幾乎是線性成長。
其實gpu本來就是這樣的線性成長特性.
問題是GT200是啥製程?65 nm
仔細想想就知道Larrabee這價構
除了相容於x86外沒有多少競爭力….
如果直接把GT200用45nm去量產恐怕更有競爭力?
未來的架構更好的製程做出比美目前的GPU的效能??
這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
也許Larrabee它跑gpgpu會勝過gpu.
但在繪圖領域,目前已經是用數百cycle的pipeline和
數百上千的THREAD去吸收DRAM的latency,
未來的規模只會更龐大.
Larrabee架構上就沒辦法做到這麼側底.
恐怕又是要求用程式技巧避開問題.
很難~
用不同製程比DIE SIZE有取巧的感覺…
等他真的量產恐怕gpu已經又增強幾倍.
畢竟GPU 6~9月就改朝換代’,cpu卻要幾年.
當年cell也是認為可以在繪圖上大顯身手,
2002年當年看起來dx8(SHADER1.0)甚至未來
GEFORCEFX也不怎麼樣….但是當CELL大展身手時
卻已經是G80的時代了.
CPU架構有很多先天包縛在,ISA要用X86恐怕限制更大.
GPU是當時主流技術量身定做的硬體.
很多部份是不可程式化的,Larrabee的好處應該是
許多功能是用軟體做,沒支援的功能可以靠軟體追加.
但效能就….
> 問題是 64core 45nm 能跑到 2Ghz 嗎? nVidia 的GTX 280 1.4B 65nm 是跑 1.3GHz,2.5B 45nm 要直上到 2GHz 問題似乎還不小
對不起我錯了,上面補充過只有不到300M,所以六倍的話就算64core也應該只有1800M不到。
而且原文應該是指面積(143mm^2),而不是電晶體數量….10core擴大到64core的話,用45nm大概是450mm^2以內。
而對Intel來說,他們看來不會做這麼大,應該是只會做32core,那應該就不到250mm^2。
因為設計差太多了,應該很難推論到底電晶體多少。
> SPE 畢竟不是單純的 vector unit,Larrabee 可以把指令大量簡化,但 SPE 最少要把 Altivec 的東西全吃下來,情況自然有些不同,當然應用的層級也不同就是。
Larrabee的指令我想不會比較簡單….
> SPE 能跑高頻應該跟是否比 Larrabee 的單元要大無關吧! 一般來說單元做的越大越耗電相對的不利高頻運作
呃,我是想成stage比較多…. Larrabee雖然沒有小到和pentium一樣只有5stages,不過聽說沒有多多少。
> 問題是 64core 45nm 能跑到 2Ghz 嗎? nVidia 的GTX 280 1.4B 65nm 是跑 1.3GHz,2.5B 45nm 要直上到 2GHz 問題似乎還不小
對不起我錯了,上面補充過只有不到300M,所以六倍的話就算64core也應該只有1800M不到。
而且原文應該是指面積(143mm^2),而不是電晶體數量….10core擴大到64core的話,用45nm大概是450mm^2以內。
而對Intel來說,他們看來不會做這麼大,應該是只會做32core,那應該就不到250mm^2。
因為設計差太多了,應該很難推論到底電晶體多少。
> SPE 畢竟不是單純的 vector unit,Larrabee 可以把指令大量簡化,但 SPE 最少要把 Altivec 的東西全吃下來,情況自然有些不同,當然應用的層級也不同就是。
Larrabee的指令我想不會比較簡單….
> SPE 能跑高頻應該跟是否比 Larrabee 的單元要大無關吧! 一般來說單元做的越大越耗電相對的不利高頻運作
呃,我是想成stage比較多…. Larrabee雖然沒有小到和pentium一樣只有5stages,不過聽說沒有多多少。
to waffenss:
感激回應XD
> 這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
Larrabee明年就要出了的東西,這句話不就代表明年N/A的產品要比現在贏個十倍?
這好像有點困難….XD
> 畢竟GPU 6~9月就改朝換代’,cpu卻要幾年.
> 當年cell也是認為可以在繪圖上大顯身手,
> 2002年當年看起來dx8(SHADER1.0)甚至未來
> GEFORCEFX也不怎麼樣….但是當CELL大展身手時
> 卻已經是G80的時代了.
事實上GPU現在也沒有哪個架構真的六到九個月就刷新,已經大半是一個架構橫跨好幾世代的產品了,這其實我覺得和CPU沒差很多;原因是因為programmable shader到現在成熟起來的時候,你也不必常常”改朝換代”來加功能了。
> 也許Larrabee它跑gpgpu會勝過gpu.
> 但在繪圖領域,目前已經是用數百cycle的pipeline和
> 數百上千的THREAD去吸收DRAM的latency,
> 未來的規模只會更龐大.
> Larrabee架構上就沒辦法做到這麼側底.
> 恐怕又是要求用程式技巧避開問題.
> 很難~
Larrabee那個Vector unit有類似NVIDIA現在提供的warp/thread分層架構,看起來也是對抗延遲用的;GPU的延遲是架構特性,是幾乎固定的長度,所以老實說有專用架構去吸收的話問題就不會很大,當然G80 -> GT200就可以知道,GPU這邊的設計能吸收的空間有限,也是要跟著需求改,Larrabee現在看起來那個fiber(vector unit的子thread)數量也不是很夠。
> CPU架構有很多先天包縛在,ISA要用X86恐怕限制更大.
> GPU是當時主流技術量身定做的硬體.
> 很多部份是不可程式化的,Larrabee的好處應該是
> 許多功能是用軟體做,沒支援的功能可以靠軟體追加.
> 但效能就….
這點不否認,不過x86我覺得其實只是為了讓一些現有的程式可以不經過大幅修改就可以跑在上面(比方說某種execution layer),這對Havok這種擺明不能跑在GPU上的東西坐地移植有點幫助。但是實際上所有的性能都是那個Vector Unit貢獻的,所以Vector Unit的部分是重點,目前看起來它有和G8x一樣的gather & scatter,就讓SIMD化輕鬆很多;現在問題就在於,如果它的LNI也是得和SSE一樣寫intrinsics的話,那麼就不會比CELL好用到哪去….CELL的問題是DMA手動管理比較煩、剩下的就是intrinsics了。
—-
結論:等實際產品出來再說XD
to waffenss:
感激回應XD
> 這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
Larrabee明年就要出了的東西,這句話不就代表明年N/A的產品要比現在贏個十倍?
這好像有點困難….XD
> 畢竟GPU 6~9月就改朝換代’,cpu卻要幾年.
> 當年cell也是認為可以在繪圖上大顯身手,
> 2002年當年看起來dx8(SHADER1.0)甚至未來
> GEFORCEFX也不怎麼樣….但是當CELL大展身手時
> 卻已經是G80的時代了.
事實上GPU現在也沒有哪個架構真的六到九個月就刷新,已經大半是一個架構橫跨好幾世代的產品了,這其實我覺得和CPU沒差很多;原因是因為programmable shader到現在成熟起來的時候,你也不必常常”改朝換代”來加功能了。
> 也許Larrabee它跑gpgpu會勝過gpu.
> 但在繪圖領域,目前已經是用數百cycle的pipeline和
> 數百上千的THREAD去吸收DRAM的latency,
> 未來的規模只會更龐大.
> Larrabee架構上就沒辦法做到這麼側底.
> 恐怕又是要求用程式技巧避開問題.
> 很難~
Larrabee那個Vector unit有類似NVIDIA現在提供的warp/thread分層架構,看起來也是對抗延遲用的;GPU的延遲是架構特性,是幾乎固定的長度,所以老實說有專用架構去吸收的話問題就不會很大,當然G80 -> GT200就可以知道,GPU這邊的設計能吸收的空間有限,也是要跟著需求改,Larrabee現在看起來那個fiber(vector unit的子thread)數量也不是很夠。
> CPU架構有很多先天包縛在,ISA要用X86恐怕限制更大.
> GPU是當時主流技術量身定做的硬體.
> 很多部份是不可程式化的,Larrabee的好處應該是
> 許多功能是用軟體做,沒支援的功能可以靠軟體追加.
> 但效能就….
這點不否認,不過x86我覺得其實只是為了讓一些現有的程式可以不經過大幅修改就可以跑在上面(比方說某種execution layer),這對Havok這種擺明不能跑在GPU上的東西坐地移植有點幫助。但是實際上所有的性能都是那個Vector Unit貢獻的,所以Vector Unit的部分是重點,目前看起來它有和G8x一樣的gather & scatter,就讓SIMD化輕鬆很多;現在問題就在於,如果它的LNI也是得和SSE一樣寫intrinsics的話,那麼就不會比CELL好用到哪去….CELL的問題是DMA手動管理比較煩、剩下的就是intrinsics了。
—-
結論:等實際產品出來再說XD
> 這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
Larrabee明年就要出了的東西,這句話不就代表明年N/A的產品要比現在贏個十倍?
這好像有點困難….XD
是真的在市場上成功銷售.而不是少量研究用.
時間點不會是明年甚至後年…
當初CELL發表也是很早,但是等它真正進入主流市場,
同時期GPU已經從GeforceFX進步到Geforce8了.
Larrabee基於CPU的天性,等它軟體面成熟時,
GT200等級恐怕已是主機板內建的小強卡了.
GPU之所以一登場就成熟度很高,跟硬體特製化很有關係,
大部份功能都是hardwire實作,根本不用去研究.
缺點是不支援的功能就是做不到,
但是那不算大問題,因為舊GPU就算能支援新功能
也跑不動…..hardwire實作當然不會浪費電晶體在
不實用的功能上.
Larrabee花在軟體上的時間恐怕比GT200的生命周期長得多,哪時候才有競爭力,而不是潛力…還很難講.
對於學術研究者 Larrabee可能很方便(CELL也是)
硬體還沒做的東西可以先軟體實作.
有些東西是被hardwire限制住的GPU辦不到的.
例如FP64繪圖?
但在主流市場….那種跑不快的技術沒有啥意義.
GPU的市場規模夠大,養得起不斷改良硬体的研發人力,
Intel在GPU設計方面比較弱,大概想一次搞定硬體,
以後只要加加核心改改軟體就好.
管它DX11,DX12….全靠軟體模禰.
> 這聽起來挺冏的,他真正對手恐怕是未來10倍校能的怪物.
Larrabee明年就要出了的東西,這句話不就代表明年N/A的產品要比現在贏個十倍?
這好像有點困難….XD
是真的在市場上成功銷售.而不是少量研究用.
時間點不會是明年甚至後年…
當初CELL發表也是很早,但是等它真正進入主流市場,
同時期GPU已經從GeforceFX進步到Geforce8了.
Larrabee基於CPU的天性,等它軟體面成熟時,
GT200等級恐怕已是主機板內建的小強卡了.
GPU之所以一登場就成熟度很高,跟硬體特製化很有關係,
大部份功能都是hardwire實作,根本不用去研究.
缺點是不支援的功能就是做不到,
但是那不算大問題,因為舊GPU就算能支援新功能
也跑不動…..hardwire實作當然不會浪費電晶體在
不實用的功能上.
Larrabee花在軟體上的時間恐怕比GT200的生命周期長得多,哪時候才有競爭力,而不是潛力…還很難講.
對於學術研究者 Larrabee可能很方便(CELL也是)
硬體還沒做的東西可以先軟體實作.
有些東西是被hardwire限制住的GPU辦不到的.
例如FP64繪圖?
但在主流市場….那種跑不快的技術沒有啥意義.
GPU的市場規模夠大,養得起不斷改良硬体的研發人力,
Intel在GPU設計方面比較弱,大概想一次搞定硬體,
以後只要加加核心改改軟體就好.
管它DX11,DX12….全靠軟體模禰.
拿 Cell 跟 Larrabee 直接類比似乎不太恰當,Cell 從一開始就沒有打算進到 PC 市場來賣,況且其硬體架構從沒有想過去相容於 DX 或是 OPGL 這些東西,這點跟 Larrabee 一開始就打算跟現有的顯卡做競爭顯然是不同的,我想 Larrabee 商品化的速度應該也不會這麼的慢,更何況即使是後年推出要做到 10 倍於 Larrabee 電晶體的產品也有相當的困難,記憶體頻寬也要到 10 倍這點從一開始就是不可能的。
Cell 的應用範圍遠比 Larrabee 設想的要廣同樣的驗證期也久很多,如果單純的以疊床架屋的想法來看以現有的 45nm 製程就足夠做到 4*cell 單晶片了,可是這樣一來的效益並不大,累積足夠的軟體資源比去追硬體規格上的
勝利要來的更重要,但 GPU 並不是這樣的,GPU 要跑的東西就都是一樣的,市場的策略差很多,CPU 的發售廠商要解決的問題太多,但 GPU 現在都跟著 API 在走,
以 Cell 來說要他們要花大量的時間在建立 SPURS,這在
Larrabee 上是不可能發生的。
Larrabee 以目前來看還是當成 GPU 來思考會比較好一些,只不過他的 VU 是 x86 based 的而已,可是硬體本身的成長性跟目標市場都跟現有的 GPU 相去不遠,只不過就看其 emu 的效能高低了。
Larrabee 的思維從 intel 過去的作法來看可能會更清楚一些,全部用 CPU 來堆這樣一來就沒有什麼 DX 或 OPGL 的問題,只要 intel 能確保在製程上領先對手,性能上也就不會太吃虧,反過來說因為沒被綁住他們要提供額外的工具給廠商用也就成了可行的了。
拿 Cell 跟 Larrabee 直接類比似乎不太恰當,Cell 從一開始就沒有打算進到 PC 市場來賣,況且其硬體架構從沒有想過去相容於 DX 或是 OPGL 這些東西,這點跟 Larrabee 一開始就打算跟現有的顯卡做競爭顯然是不同的,我想 Larrabee 商品化的速度應該也不會這麼的慢,更何況即使是後年推出要做到 10 倍於 Larrabee 電晶體的產品也有相當的困難,記憶體頻寬也要到 10 倍這點從一開始就是不可能的。
Cell 的應用範圍遠比 Larrabee 設想的要廣同樣的驗證期也久很多,如果單純的以疊床架屋的想法來看以現有的 45nm 製程就足夠做到 4*cell 單晶片了,可是這樣一來的效益並不大,累積足夠的軟體資源比去追硬體規格上的
勝利要來的更重要,但 GPU 並不是這樣的,GPU 要跑的東西就都是一樣的,市場的策略差很多,CPU 的發售廠商要解決的問題太多,但 GPU 現在都跟著 API 在走,
以 Cell 來說要他們要花大量的時間在建立 SPURS,這在
Larrabee 上是不可能發生的。
Larrabee 以目前來看還是當成 GPU 來思考會比較好一些,只不過他的 VU 是 x86 based 的而已,可是硬體本身的成長性跟目標市場都跟現有的 GPU 相去不遠,只不過就看其 emu 的效能高低了。
Larrabee 的思維從 intel 過去的作法來看可能會更清楚一些,全部用 CPU 來堆這樣一來就沒有什麼 DX 或 OPGL 的問題,只要 intel 能確保在製程上領先對手,性能上也就不會太吃虧,反過來說因為沒被綁住他們要提供額外的工具給廠商用也就成了可行的了。
我想的CELL不完全是目前這個CELL.
當時有規劃特製化GPU型的cell.
“Cell Visualizer”
架構有些類似….4ppe+32spe+大量TEX和ROP.
明顯想跟顯卡做競爭,但最後也沒做了.
Larrabee雖然應用上要當成GPU來思考
但是架構上仍然是CPU,也就是短pipeline,
和CPU相似的指令集,少量的thread,共用的大量cache….
很像當時規劃的Cell Visualizer.
Cell Visualizer也是以GPU的角度去設計的.
把Tex unit內建.靠大量的SPE來實作其他繪圖功能.
GPU能跑到這麼高的輸出校能,
靠的是極高DRAM頻寬,以及非常能容忍Latency的
硬體架構, GF6時代就已經有256stage pipeline,
上百個thread,只要遇到texture存取,立刻跳到另一個
thread,幾百cycle再回來接收texel繼續計算.
Cell Visualizer和larrabee都沒有辦法這樣搞.
雖然也內建tex unit,
但是沒有足夠的thread和pipelne長度去隱藏latency.
(足夠的意思是至少數百….因為記憶體就是這麼慢)
想要高輸出能力就要有辦法有大量頻寬和latency容忍性.
但不管是Cell Visualizer和larrabee都沒有看到很好的解決辦法….
Cell Visualizer當時看法也是可以拿來做一些
研究用途,或是跑renderman shader.
藉由半軟半硬的架構,可以做一些hardwire硬體還不能做的,但是又跑的比純軟體演算快的多.
我想的CELL不完全是目前這個CELL.
當時有規劃特製化GPU型的cell.
“Cell Visualizer”
架構有些類似….4ppe+32spe+大量TEX和ROP.
明顯想跟顯卡做競爭,但最後也沒做了.
Larrabee雖然應用上要當成GPU來思考
但是架構上仍然是CPU,也就是短pipeline,
和CPU相似的指令集,少量的thread,共用的大量cache….
很像當時規劃的Cell Visualizer.
Cell Visualizer也是以GPU的角度去設計的.
把Tex unit內建.靠大量的SPE來實作其他繪圖功能.
GPU能跑到這麼高的輸出校能,
靠的是極高DRAM頻寬,以及非常能容忍Latency的
硬體架構, GF6時代就已經有256stage pipeline,
上百個thread,只要遇到texture存取,立刻跳到另一個
thread,幾百cycle再回來接收texel繼續計算.
Cell Visualizer和larrabee都沒有辦法這樣搞.
雖然也內建tex unit,
但是沒有足夠的thread和pipelne長度去隱藏latency.
(足夠的意思是至少數百….因為記憶體就是這麼慢)
想要高輸出能力就要有辦法有大量頻寬和latency容忍性.
但不管是Cell Visualizer和larrabee都沒有看到很好的解決辦法….
Cell Visualizer當時看法也是可以拿來做一些
研究用途,或是跑renderman shader.
藉由半軟半硬的架構,可以做一些hardwire硬體還不能做的,但是又跑的比純軟體演算快的多.
當年製程做不到,很多東西自然就生不出來了。
雖說 CPU 沒有超大量的 thread 但是反過來說他們卻有大容量的 cache,這點跟 GPU 又有所不同了,至於是否能有效的解決問題,就要再看看之後成品如何了。
太早說成功或失敗都不見得準確,路還很長的。
當年製程做不到,很多東西自然就生不出來了。
雖說 CPU 沒有超大量的 thread 但是反過來說他們卻有大容量的 cache,這點跟 GPU 又有所不同了,至於是否能有效的解決問題,就要再看看之後成品如何了。
太早說成功或失敗都不見得準確,路還很長的。
作成CPU的延伸似乎也是一個市場
把原本CPU的工作丟給Larrabee去算
就像是變相的GPGPU運算
優點是x86下軟體資源豐富
繪圖上也有不錯的效率
這樣好像只是把CPU板卡化
主板上的CPU位置變成一個橋接晶片這樣XD
但是使用者需不需要這麼快的CPU應該是最大難題
總之這是一個高高端產品是不會錯的
intel、AMD、nV都用自己的方法想跳出來
只是AMD的部份手腳好像慢了點
nV則是滿空氣的XD
作成CPU的延伸似乎也是一個市場
把原本CPU的工作丟給Larrabee去算
就像是變相的GPGPU運算
優點是x86下軟體資源豐富
繪圖上也有不錯的效率
這樣好像只是把CPU板卡化
主板上的CPU位置變成一個橋接晶片這樣XD
但是使用者需不需要這麼快的CPU應該是最大難題
總之這是一個高高端產品是不會錯的
intel、AMD、nV都用自己的方法想跳出來
只是AMD的部份手腳好像慢了點
nV則是滿空氣的XD
> 雖說 CPU 沒有超大量的 thread 但是反過來說他們卻有大容量的 cache,這點跟 GPU 又有所不同了,至於是否能有效的解決問題,就要再看看之後成品如何了。
我也覺得cache是重點。
上面說NV40有長stage的ROP pipeline和thread數量,但是說真的,規模更龐大的G8x每個TPC也才32KB的register file提供8192個thread、GT200則是64KB,而每個TPC事實上都要自行面對記憶體的延遲,和用ring bus的Larrabee不太一樣,Larrabee應該有辦法做到過去CELL想做的”每個SPE連接起來構成pipeline”,所以如果Larrabee透過cache和Vector unit的register來提供類似功能的模擬,我覺得不會很意外就是了。
當然這樣說的話CELL也有256KB的LS,理應可以做出類似的機制,但是最後沒有人做….
> 雖說 CPU 沒有超大量的 thread 但是反過來說他們卻有大容量的 cache,這點跟 GPU 又有所不同了,至於是否能有效的解決問題,就要再看看之後成品如何了。
我也覺得cache是重點。
上面說NV40有長stage的ROP pipeline和thread數量,但是說真的,規模更龐大的G8x每個TPC也才32KB的register file提供8192個thread、GT200則是64KB,而每個TPC事實上都要自行面對記憶體的延遲,和用ring bus的Larrabee不太一樣,Larrabee應該有辦法做到過去CELL想做的”每個SPE連接起來構成pipeline”,所以如果Larrabee透過cache和Vector unit的register來提供類似功能的模擬,我覺得不會很意外就是了。
當然這樣說的話CELL也有256KB的LS,理應可以做出類似的機制,但是最後沒有人做….
> “Cell Visualizer”
> 架構有些類似….4ppe+32spe+大量TEX和ROP.
> 明顯想跟顯卡做競爭,但最後也沒做了.
當年的CELL可是4PE的大玩意兒….那和現在的PowerXCell 32iv是差不多的東西;然後CELL Visualizer是在那個大CELL的基礎上,刪除一些SPE之後掛上TMU和ROP的設計,那老實說從現在的觀點來看還是很大的東西。
> “Cell Visualizer”
> 架構有些類似….4ppe+32spe+大量TEX和ROP.
> 明顯想跟顯卡做競爭,但最後也沒做了.
當年的CELL可是4PE的大玩意兒….那和現在的PowerXCell 32iv是差不多的東西;然後CELL Visualizer是在那個大CELL的基礎上,刪除一些SPE之後掛上TMU和ROP的設計,那老實說從現在的觀點來看還是很大的東西。
認同Eji,使用45nm時,32核心
認同Eji,使用45nm時,32核心
但是性能就難說了, 僅僅測試了25幀,也就是25個畫面而已.而且是用軟體模擬的!! 使用trace采集技術透過模擬器軟體來模擬,并非硬件執行.還有,它是使用單核模擬器來模擬的,多核之間的同步開銷沒有計入–等于沒有性能預覽,無任何可比性.
但是性能就難說了, 僅僅測試了25幀,也就是25個畫面而已.而且是用軟體模擬的!! 使用trace采集技術透過模擬器軟體來模擬,并非硬件執行.還有,它是使用單核模擬器來模擬的,多核之間的同步開銷沒有計入–等于沒有性能預覽,無任何可比性.
以ibm的實力,是沒有能力制造合理成本范圍內的GPU的.設計能力差遠了!! 其依靠的是硬件虧本用軟件撈回.而GPU市場沒有什么機會!!
以ibm的實力,是沒有能力制造合理成本范圍內的GPU的.設計能力差遠了!! 其依靠的是硬件虧本用軟件撈回.而GPU市場沒有什么機會!!
比較合理的性能猜測是: 對于已經上市的游戲而言,當larrabee的x86/16-simd-vpu核心數量等于GTX280的Streaming Multiprocessor(SM,含8個SP)數量時, 1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/6.
對于未來一些DX11使用大量compute shader的游戲而言,1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/2.
larrabee的優勢是compute shader,采取合適的編程可以比GTX280更有效利用數據局部性。
比較合理的性能猜測是: 對于已經上市的游戲而言,當larrabee的x86/16-simd-vpu核心數量等于GTX280的Streaming Multiprocessor(SM,含8個SP)數量時, 1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/6.
對于未來一些DX11使用大量compute shader的游戲而言,1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/2.
larrabee的優勢是compute shader,采取合適的編程可以比GTX280更有效利用數據局部性。
Cell 總運算量不夠要做到跟 Larrabee 一樣的事是不太可能的,換個方面想如果 Larrabee 是個 250M 大小的產品要做顯卡某方面也會顯得非常的不利。
另一方面是遊戲上 Cell 是配 RSX 來用的,拿 Cell 來跑全部的 shader 只是一種浪費而已,現在只是看 Cell 的 Geometry Processing 能做到什麼程度而已,畢竟真要用他去建立多邊型或是跑 PS 都算是一種浪費吧!
Cell 總運算量不夠要做到跟 Larrabee 一樣的事是不太可能的,換個方面想如果 Larrabee 是個 250M 大小的產品要做顯卡某方面也會顯得非常的不利。
另一方面是遊戲上 Cell 是配 RSX 來用的,拿 Cell 來跑全部的 shader 只是一種浪費而已,現在只是看 Cell 的 Geometry Processing 能做到什麼程度而已,畢竟真要用他去建立多邊型或是跑 PS 都算是一種浪費吧!
> 另一方面是遊戲上 Cell 是配 RSX 來用的,拿 Cell 來跑全部的 shader 只是一種浪費而已,現在只是看 Cell 的 Geometry Processing 能做到什麼程度而已,畢竟真要用他去建立多邊型或是跑 PS 都算是一種浪費吧!
但是這時候就會顯得用CELL來跑Geometry Shader意義不大,因為FlexIO….
你用CELL跑得越複雜,RSX本身的VS就還是得處理那麼多資料。說起來Geometry Shader,還有DX11引入的Hull shader、Tessellation stage之類的GS發展型,都算是一種polaygon data的壓縮,但是RSX在輸入端並沒有那麼大的能力,FlexIO是G7x原始的輸入頻寬 + Frame buffer(Turbu cache)的總頻寬,所以我很懷疑RSX能不能吃下來….(用VTF讓VS讀進來的話又會有VS本身這時候更慢的問題)
—-
>對于已經上市的游戲而言,當larrabee的x86/16-simd-vpu核心數量等于GTX280的Streaming Multiprocessor(SM,含8個SP)數量時, 1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/6.
為什麼是1/6呢….?
我不懂怎麼算的,因為GTX280顯然是不會超頻到1GHz,它本身fix pipeline橫向擴充的同時,時脈就沒有比過去的產品還高,但如果你說shader是1GHz的話,那反而是降頻了。
不過如果我把GTX280的shader設定在1.5GHz、core設定在600MHz(比現在稍高)的話,那可能會比現在快個15~20%…. 而以你上面提到的”16simd”數量相同的狀況來說的話,那相當於15個Larrabee core運作在1GHz,以Intel的說法這大概是”HL2 EP2可以執行到16×12 4xAA 90fps”的程度(他們宣稱HL2 EP2可以用10core達到min60fps),但是GTX280(即使oc這20%)能夠把HL2 EP2給run到min540fps(max的話可能就超過1000fps了,因為Larrabee在max用5core就跑60fps了)?好像有點可疑….
(反過來說,光是32core就已經有32個16way SIMD跑在2GHz了….)
當然,Intel用一個core算一個frame要算多久、反過來推”幾個core能跑出多少性能”,這就像是”一個G8x TPC能跑出多少性能,所以只要裝幾個TPC就有跑出多少性能”的說法,但是這就忽視掉記憶體頻寬、內部通訊頻寬的影響了,更何況NVIDIA是在裡面用crossbar、但是Intel可是用ring bus呢。
> 對于未來一些DX11使用大量compute shader的游戲而言,1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/2.
這我也看不太懂來源….XDa
> 另一方面是遊戲上 Cell 是配 RSX 來用的,拿 Cell 來跑全部的 shader 只是一種浪費而已,現在只是看 Cell 的 Geometry Processing 能做到什麼程度而已,畢竟真要用他去建立多邊型或是跑 PS 都算是一種浪費吧!
但是這時候就會顯得用CELL來跑Geometry Shader意義不大,因為FlexIO….
你用CELL跑得越複雜,RSX本身的VS就還是得處理那麼多資料。說起來Geometry Shader,還有DX11引入的Hull shader、Tessellation stage之類的GS發展型,都算是一種polaygon data的壓縮,但是RSX在輸入端並沒有那麼大的能力,FlexIO是G7x原始的輸入頻寬 + Frame buffer(Turbu cache)的總頻寬,所以我很懷疑RSX能不能吃下來….(用VTF讓VS讀進來的話又會有VS本身這時候更慢的問題)
—-
>對于已經上市的游戲而言,當larrabee的x86/16-simd-vpu核心數量等于GTX280的Streaming Multiprocessor(SM,含8個SP)數量時, 1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/6.
為什麼是1/6呢….?
我不懂怎麼算的,因為GTX280顯然是不會超頻到1GHz,它本身fix pipeline橫向擴充的同時,時脈就沒有比過去的產品還高,但如果你說shader是1GHz的話,那反而是降頻了。
不過如果我把GTX280的shader設定在1.5GHz、core設定在600MHz(比現在稍高)的話,那可能會比現在快個15~20%…. 而以你上面提到的”16simd”數量相同的狀況來說的話,那相當於15個Larrabee core運作在1GHz,以Intel的說法這大概是”HL2 EP2可以執行到16×12 4xAA 90fps”的程度(他們宣稱HL2 EP2可以用10core達到min60fps),但是GTX280(即使oc這20%)能夠把HL2 EP2給run到min540fps(max的話可能就超過1000fps了,因為Larrabee在max用5core就跑60fps了)?好像有點可疑….
(反過來說,光是32core就已經有32個16way SIMD跑在2GHz了….)
當然,Intel用一個core算一個frame要算多久、反過來推”幾個core能跑出多少性能”,這就像是”一個G8x TPC能跑出多少性能,所以只要裝幾個TPC就有跑出多少性能”的說法,但是這就忽視掉記憶體頻寬、內部通訊頻寬的影響了,更何況NVIDIA是在裡面用crossbar、但是Intel可是用ring bus呢。
> 對于未來一些DX11使用大量compute shader的游戲而言,1GHz的larrabee的性能僅為GTX280(超頻@1GHz)的1/2.
這我也看不太懂來源….XDa
> 但是性能就難說了, 僅僅測試了25幀,也就是25個畫面而已.而且是用軟體模擬的!!
> 使用trace采集技術透過模擬器軟體來模擬,并非硬件執行.還有,它是使用單核模擬器來模擬的,多核之間的同步開銷沒有計入–等于沒有性能預覽,無任何可比性.
我不會這樣覺得耶,每個frame在一個架構上需要跑多少時間(60fps = 15ms per frame)算是有一定的參考價值,反正game developer其實也是這樣optimize的。
不然的話,這世上就沒有哪個cycle-accurate simulator有意義了。
> 以ibm的實力,是沒有能力制造合理成本范圍內的GPU的.設計能力差遠了!!
> 其依靠的是硬件虧本用軟件撈回.而GPU市場沒有什么機會!!
他們先前的FireGL team已經轉手出去許多年了,現在當然是從頭開始….而當初他們也是想買IP core進來放的,所以那個graphic部分到底長什麼樣子是完全付之闕如。
不過這和IBM的”實力”是沒有關係的。STI的目的還是要做出一個異質處理架構,一個有高度擴充性的DSP之故,用這去”譏笑”IBM的”實力”,老實說是不太適當。
> 但是性能就難說了, 僅僅測試了25幀,也就是25個畫面而已.而且是用軟體模擬的!!
> 使用trace采集技術透過模擬器軟體來模擬,并非硬件執行.還有,它是使用單核模擬器來模擬的,多核之間的同步開銷沒有計入–等于沒有性能預覽,無任何可比性.
我不會這樣覺得耶,每個frame在一個架構上需要跑多少時間(60fps = 15ms per frame)算是有一定的參考價值,反正game developer其實也是這樣optimize的。
不然的話,這世上就沒有哪個cycle-accurate simulator有意義了。
> 以ibm的實力,是沒有能力制造合理成本范圍內的GPU的.設計能力差遠了!!
> 其依靠的是硬件虧本用軟件撈回.而GPU市場沒有什么機會!!
他們先前的FireGL team已經轉手出去許多年了,現在當然是從頭開始….而當初他們也是想買IP core進來放的,所以那個graphic部分到底長什麼樣子是完全付之闕如。
不過這和IBM的”實力”是沒有關係的。STI的目的還是要做出一個異質處理架構,一個有高度擴充性的DSP之故,用這去”譏笑”IBM的”實力”,老實說是不太適當。
解說的詳細點: Eji明顯看高了larrabee的性能.
標準GTX 280@0.6GHz/SP@1.3G–含有30個SM
按超級理想情況超频@1GHz/SP@約2GHz的規格.
如果larrabee也是含有30個x86核心、即同時含有30個16 way simd的vpu(Eji似乎對此有歧義?)的條件下,1GHz的larrabee的性能僅為GTX280@1G的1/6.(已經上市的游戲的性能)
而未來DX11的游戲,并且是運用大量compute shader的游戲里–情況可能變為1/2. larrabee優勢是compute shader.
解說的詳細點: Eji明顯看高了larrabee的性能.
標準GTX 280@0.6GHz/SP@1.3G–含有30個SM
按超級理想情況超频@1GHz/SP@約2GHz的規格.
如果larrabee也是含有30個x86核心、即同時含有30個16 way simd的vpu(Eji似乎對此有歧義?)的條件下,1GHz的larrabee的性能僅為GTX280@1G的1/6.(已經上市的游戲的性能)
而未來DX11的游戲,并且是運用大量compute shader的游戲里–情況可能變為1/2. larrabee優勢是compute shader.
就用軟體模擬25幀,能說明什么? 僅僅是25幀. 僅僅是25幀,能說明什么??
大笑話啊,一個游戲一段場景有上萬幀. 好無可比性.
而且是單核模擬器, 能說明問題? 實際情況下,計算任務無可能平均分割, 假如計算任務要被分割到32個核心里執行,但是由最慢的計算量最大的那個load負荷來決定幀數(令人頭痛的load平衡). 使用單核心模擬器,等于就是假設計算量絕對理想化分割–其模擬出來的性能與實際性能可能差別2倍或更高. 毫無實際意義!!
就用軟體模擬25幀,能說明什么? 僅僅是25幀. 僅僅是25幀,能說明什么??
大笑話啊,一個游戲一段場景有上萬幀. 好無可比性.
而且是單核模擬器, 能說明問題? 實際情況下,計算任務無可能平均分割, 假如計算任務要被分割到32個核心里執行,但是由最慢的計算量最大的那個load負荷來決定幀數(令人頭痛的load平衡). 使用單核心模擬器,等于就是假設計算量絕對理想化分割–其模擬出來的性能與實際性能可能差別2倍或更高. 毫無實際意義!!
>FlexIO是G7x原始的輸入頻寬 + Frame buffer(Turbu cache)的總頻寬
這是否表示Cell給RSX的資料,
如果不經由GDDR3,
直接丟給RSX是只有”G7x原始的輸入頻寬”,
而非FlexIO接RSX的總頻寬?
>FlexIO是G7x原始的輸入頻寬 + Frame buffer(Turbu cache)的總頻寬
這是否表示Cell給RSX的資料,
如果不經由GDDR3,
直接丟給RSX是只有”G7x原始的輸入頻寬”,
而非FlexIO接RSX的總頻寬?
先說larrabee的vpu指令集isa,其類似x86的 vreg0=vreg1- [memory]運算,雖然有點特色,但是整體效率如何能與GTX280的isa相比??
larrabee是16 way simd,shader里面有16way平行的機會遠遠小于8way平行? 如何與GTX280的SM相比? 何況SM的底層是8個標量scalar SP,比8 way simd更為靈活高效?
larrabee的多線程就更無效率優勢了,每個核心僅有4個線程,更可悲的是3個線程是給shader計算用的,還有一個是干其他任務兼管理. 能與GTX280的超多線程相比??
larrabee所需計算量遠遠高于GTX280,由于其軟件渲染完成光柵ROP等!
40%的運算力由于軟件代替hardwire的光柵/rop等等而浪費了. 而由于isa與線程弱點其shader計算的效率遠遠低于GTX280,按超級理想假設larrabee的效率能有GTX280的25%. 兩個結果疊加后是什么?? 你可以計算一下.
恐怕是@1GHz對比時,larrabee還要遠遠低于GTX280的1/6吧?
先說larrabee的vpu指令集isa,其類似x86的 vreg0=vreg1- [memory]運算,雖然有點特色,但是整體效率如何能與GTX280的isa相比??
larrabee是16 way simd,shader里面有16way平行的機會遠遠小于8way平行? 如何與GTX280的SM相比? 何況SM的底層是8個標量scalar SP,比8 way simd更為靈活高效?
larrabee的多線程就更無效率優勢了,每個核心僅有4個線程,更可悲的是3個線程是給shader計算用的,還有一個是干其他任務兼管理. 能與GTX280的超多線程相比??
larrabee所需計算量遠遠高于GTX280,由于其軟件渲染完成光柵ROP等!
40%的運算力由于軟件代替hardwire的光柵/rop等等而浪費了. 而由于isa與線程弱點其shader計算的效率遠遠低于GTX280,按超級理想假設larrabee的效率能有GTX280的25%. 兩個結果疊加后是什么?? 你可以計算一下.
恐怕是@1GHz對比時,larrabee還要遠遠低于GTX280的1/6吧?
Cell+RSX 的總運算量僅有 RV700 跟 GTX280 的一半,跟 DX11 世代的產品比就差更多了,考量到他們整體的運算量跟記憶體總量以及總頻寬就可發現他們仍是那個世代的產品,GS 很大的一個功用的確是多邊型資料的壓縮,但如果我們從 DAO 跟變型影或是 Reflection mapping 這一類的來看的話就似乎不是這樣了,我想問題應該不會卡在頻寬,反而是 VS 本身的上限會是瓶頸的所在,不可否認的是基本的 vertex 數目跟多邊型建立能力取決於 VS 運算能力的上限,用 Cell 去做預處理只是一種最佳化而已,但反過來說不用 Cell 去處理,一些變型或是光源遮蔽之類的東西要 RSX 去做都顯得不可能。
用 Cell 去跑只是讓他們能多點效果,在同級解析度上做出不一樣的表現而已,要跟新的顯卡比還是有所困難,但反過來說因為輸出解析度較低的關係這影響也就不是那麼的大了。
話說回來就算 6*SPE 全都去跑,也才不過 144G 的處理量,況且還要先做壓縮/解壓的動作以及 Culling 的預處理,總資料量應該不會大到超過 FlexIO 的總頻寬。
Cell+RSX 的總運算量僅有 RV700 跟 GTX280 的一半,跟 DX11 世代的產品比就差更多了,考量到他們整體的運算量跟記憶體總量以及總頻寬就可發現他們仍是那個世代的產品,GS 很大的一個功用的確是多邊型資料的壓縮,但如果我們從 DAO 跟變型影或是 Reflection mapping 這一類的來看的話就似乎不是這樣了,我想問題應該不會卡在頻寬,反而是 VS 本身的上限會是瓶頸的所在,不可否認的是基本的 vertex 數目跟多邊型建立能力取決於 VS 運算能力的上限,用 Cell 去做預處理只是一種最佳化而已,但反過來說不用 Cell 去處理,一些變型或是光源遮蔽之類的東西要 RSX 去做都顯得不可能。
用 Cell 去跑只是讓他們能多點效果,在同級解析度上做出不一樣的表現而已,要跟新的顯卡比還是有所困難,但反過來說因為輸出解析度較低的關係這影響也就不是那麼的大了。
話說回來就算 6*SPE 全都去跑,也才不過 144G 的處理量,況且還要先做壓縮/解壓的動作以及 Culling 的預處理,總資料量應該不會大到超過 FlexIO 的總頻寬。
spe是卡在延遲上了!! 用SPE作VS或GS,然后透過 FlexIO送到RSX的GDDR3顯存里,RSX還要從GDDR3顯存讀取它們,延遲太大了,幾千個cycles,根本無實際效能體現.
而SPE的運算力也太低了,并且指令效率低下,起碼比GPU要低20%以下. SPE可以游戲物理,想提速VS或GS? 減速倒是真的.
實際世界里的ibm哪里有哪個實力?? 偶像派.
spe是卡在延遲上了!! 用SPE作VS或GS,然后透過 FlexIO送到RSX的GDDR3顯存里,RSX還要從GDDR3顯存讀取它們,延遲太大了,幾千個cycles,根本無實際效能體現.
而SPE的運算力也太低了,并且指令效率低下,起碼比GPU要低20%以下. SPE可以游戲物理,想提速VS或GS? 減速倒是真的.
實際世界里的ibm哪里有哪個實力?? 偶像派.
很多ps3的游戲開發者就是ps2時代的游戲開發者,他們是優化行家,對硬件復雜度的鉆研度遠遠高于任何局外人.
這么多年來,他們為ps3絞盡了腦汁,都沒有取得實質性突破,spe的現實–其運算力對于GPU而言就是水中月.
何況很多GS一般是需要先進行VS后,才開始計算GS–如此情形下,難道你讓RSX先計算VS,結果寫到GDDR3顯存,然后透過FlexIO送到系統內存里,然后SPE讀系統內存,計算GS,然后透過FlexIO送到GDDR3顯存,RSX讀GDDR3顯存后繼續后續處理? 結果就是超級減速!!
或者,SPE既要計算GS也要完成VS,結果透過FlexIO寫到GDDR3顯存…… 還是相當低效.
很多ps3的游戲開發者就是ps2時代的游戲開發者,他們是優化行家,對硬件復雜度的鉆研度遠遠高于任何局外人.
這么多年來,他們為ps3絞盡了腦汁,都沒有取得實質性突破,spe的現實–其運算力對于GPU而言就是水中月.
何況很多GS一般是需要先進行VS后,才開始計算GS–如此情形下,難道你讓RSX先計算VS,結果寫到GDDR3顯存,然后透過FlexIO送到系統內存里,然后SPE讀系統內存,計算GS,然后透過FlexIO送到GDDR3顯存,RSX讀GDDR3顯存后繼續后續處理? 結果就是超級減速!!
或者,SPE既要計算GS也要完成VS,結果透過FlexIO寫到GDDR3顯存…… 還是相當低效.
Cell存取GDDR3記得毫無效率可言,比較可行的是放
在主記憶體,RSX再去拉來用。
Cell存取GDDR3記得毫無效率可言,比較可行的是放
在主記憶體,RSX再去拉來用。
> 按超級理想假設larrabee的效率能有GTX280的25%
原來如此,這就是你算出1/6的理由啊。
1. 運算當量效率只算成1/4
2. ROP再疊到core這邊來。
事實上G80/GT200主要的優勢就是在於8sp的gather & scatter,能夠帶來SIMD化的高效率….問題是Larrabee是有gather & scatter和mask register的。
所以我覺得那16way SIMD效率不會低到太誇張。
至於大家都看得到SMT x4,卻沒有看到vector register裡面的fiber自訂線程(8個可變寬度的register file,其實應該可以看成nvidia的8warp),由於它有指出用來隱蔽”已知長度的長延遲”,可以確定那是針對GDDR5等記憶體頻寬的延遲。
所以4SMT是針對x86程式內的延遲設計的,所謂”短而不可預知的延遲”。所以SMT for GPGPU/x86、fiber for graphic。
另外,我是蠻同意ROP的損耗應該會耗掉不少Larrabee的運算量,不過Intel還是可以在指令集裡面設ROP專用的加速指令,這邊真的要等ISA公布才知道結果,畢竟blending之類的東西真的不難….
難其實是難在TMU。
—-
話說這樣一路看下來好像變成我在替Larrabee辯護,奇怪我不是N飯嗎XD
—-
CELL的動作還是寫回XDR然後讓RSX自己去抓比較好….
> 按超級理想假設larrabee的效率能有GTX280的25%
原來如此,這就是你算出1/6的理由啊。
1. 運算當量效率只算成1/4
2. ROP再疊到core這邊來。
事實上G80/GT200主要的優勢就是在於8sp的gather & scatter,能夠帶來SIMD化的高效率….問題是Larrabee是有gather & scatter和mask register的。
所以我覺得那16way SIMD效率不會低到太誇張。
至於大家都看得到SMT x4,卻沒有看到vector register裡面的fiber自訂線程(8個可變寬度的register file,其實應該可以看成nvidia的8warp),由於它有指出用來隱蔽”已知長度的長延遲”,可以確定那是針對GDDR5等記憶體頻寬的延遲。
所以4SMT是針對x86程式內的延遲設計的,所謂”短而不可預知的延遲”。所以SMT for GPGPU/x86、fiber for graphic。
另外,我是蠻同意ROP的損耗應該會耗掉不少Larrabee的運算量,不過Intel還是可以在指令集裡面設ROP專用的加速指令,這邊真的要等ISA公布才知道結果,畢竟blending之類的東西真的不難….
難其實是難在TMU。
—-
話說這樣一路看下來好像變成我在替Larrabee辯護,奇怪我不是N飯嗎XD
—-
CELL的動作還是寫回XDR然後讓RSX自己去抓比較好….
>>NV40有長stage的ROP pipeline和thread數量,但是說真的,
>>規模更龐大的G8x每個TPC也才32KB的register file提供8192個thread、
>>GT200則是64KB,而每個TPC事實上都要自行面對記憶體的延遲,
>>和用ring bus的Larrabee不太一樣,Larrabee應該有辦法做到
>>過去CELL想做的”每個SPE連接起來構成pipeline”,
>>所以如果Larrabee透過cache和Vector unit的register來提供
>>類似功能的模擬,我覺得不會很意外就是了。
>>當然這樣說的話CELL也有256KB的LS,理應可以做出類似的機制,但是最後沒有人做….
GPU的register file很小,因為設計上就是要讓每個thread只需用很少的register.
nvidia在shader的最佳化文件裡面就說,如果你讓shader用的register數量超過硬體最佳的數字,
那你實質可用的thread就會變少,而影響效能.
假設硬體有1000個thread,register file只夠分到每個thread有8組register.
當你用了16組register,硬體就只有500thread可以同時運作.
所以開發者要儘量用少一點register去寫shader.
早期的DX9 GPU甚至必須靠fp16來減半register pressure.
因為fp32太大,佔用加倍的register,會導致硬體thread數量不夠.
GPU減少記憶體latency的影響主要靠的是thread的數量.
cache大小對GPU而言較不明顯,因為繪圖的資料吞吐量太大,隨便一個小貼圖都遠超過cache的容量.
即始再加大10倍也會一直cache miss.
GPU設計上就靠大量的thread切換,等幾百cycle後再回來繼續處理,隱藏記憶體的latency
當然GPU這麼多的thread分配給很多計算單位,平均每個單位只配到數十個thread.
但跟CPU一般只有1~4thread相比,在記憶體延遲的容忍度上還是有極大優勢.
Larrabee和Cell Visualizer都不可能這麼多thread,
CPU的一個thread可用的register很多,cache也更大.
但是我想像不出Larrabee透過cache和Vector unit的register來提供類似功能的模擬要怎麼做,
畢竟那是硬體的東西,要用軟體來做,恐怕效率上有困難.
另外…如果larrabee要等同GT280,那必須有明顯超過GT280的運算能力.
因為除了負擔同樣的shader運算量,larrabee還必須模擬ROP的blending,
模擬MSAA resolve,模擬Triangle setup,模擬culling&Clipping……
在GT280上這些都是hardwire的,可以視為免費的運算.
而larrabee要分出不少運算能力處理這一塊.
雖然可能有特殊指令去加速,但是跟免費的hardwire還是有差.
就看它在運算能力領先程度是否大到能cover這個不利因素了.
>>NV40有長stage的ROP pipeline和thread數量,但是說真的,
>>規模更龐大的G8x每個TPC也才32KB的register file提供8192個thread、
>>GT200則是64KB,而每個TPC事實上都要自行面對記憶體的延遲,
>>和用ring bus的Larrabee不太一樣,Larrabee應該有辦法做到
>>過去CELL想做的”每個SPE連接起來構成pipeline”,
>>所以如果Larrabee透過cache和Vector unit的register來提供
>>類似功能的模擬,我覺得不會很意外就是了。
>>當然這樣說的話CELL也有256KB的LS,理應可以做出類似的機制,但是最後沒有人做….
GPU的register file很小,因為設計上就是要讓每個thread只需用很少的register.
nvidia在shader的最佳化文件裡面就說,如果你讓shader用的register數量超過硬體最佳的數字,
那你實質可用的thread就會變少,而影響效能.
假設硬體有1000個thread,register file只夠分到每個thread有8組register.
當你用了16組register,硬體就只有500thread可以同時運作.
所以開發者要儘量用少一點register去寫shader.
早期的DX9 GPU甚至必須靠fp16來減半register pressure.
因為fp32太大,佔用加倍的register,會導致硬體thread數量不夠.
GPU減少記憶體latency的影響主要靠的是thread的數量.
cache大小對GPU而言較不明顯,因為繪圖的資料吞吐量太大,隨便一個小貼圖都遠超過cache的容量.
即始再加大10倍也會一直cache miss.
GPU設計上就靠大量的thread切換,等幾百cycle後再回來繼續處理,隱藏記憶體的latency
當然GPU這麼多的thread分配給很多計算單位,平均每個單位只配到數十個thread.
但跟CPU一般只有1~4thread相比,在記憶體延遲的容忍度上還是有極大優勢.
Larrabee和Cell Visualizer都不可能這麼多thread,
CPU的一個thread可用的register很多,cache也更大.
但是我想像不出Larrabee透過cache和Vector unit的register來提供類似功能的模擬要怎麼做,
畢竟那是硬體的東西,要用軟體來做,恐怕效率上有困難.
另外…如果larrabee要等同GT280,那必須有明顯超過GT280的運算能力.
因為除了負擔同樣的shader運算量,larrabee還必須模擬ROP的blending,
模擬MSAA resolve,模擬Triangle setup,模擬culling&Clipping……
在GT280上這些都是hardwire的,可以視為免費的運算.
而larrabee要分出不少運算能力處理這一塊.
雖然可能有特殊指令去加速,但是跟免費的hardwire還是有差.
就看它在運算能力領先程度是否大到能cover這個不利因素了.
http://tinyurl.com/6xbrus
某方面來說,與其說是他跑完 GS+VS 不如說他只是在幫給 VS 吃的資料給最佳化而已,並不是什麼神奇的東西,但也不會說一無事處,以 SCEI 自己放出的數據來說,同樣記憶體下可壓縮6.5倍的多邊型,Culling 約快上 10%~20%,Shadow map 則是快上 70%,Skinning 則為 30%,但這些都是以 RSX 為基準來做比較的,相較於現在的新產品而言還是慢。
http://tinyurl.com/6xbrus
某方面來說,與其說是他跑完 GS+VS 不如說他只是在幫給 VS 吃的資料給最佳化而已,並不是什麼神奇的東西,但也不會說一無事處,以 SCEI 自己放出的數據來說,同樣記憶體下可壓縮6.5倍的多邊型,Culling 約快上 10%~20%,Shadow map 則是快上 70%,Skinning 則為 30%,但這些都是以 RSX 為基準來做比較的,相較於現在的新產品而言還是慢。
> 所以我覺得那16way SIMD效率不會低到太誇張。
肯定要比8way simd低上很多
>至於大家都看得到SMT x4,卻沒有看到vector register裡面的fiber自訂線程(8個可變寬度的register file,其實應該可以看成nvidia的8warp),由於它有指出用來隱蔽”已知長度的長延遲”,可以確定那是針對GDDR5等記憶體頻寬的延遲。
看原文Larrabee: A Many-Core x86 Architecture for Visual Computing
the setup thread issues pixels to the work threads in groups of 16 that we call a qquad.
This is hidden by computing
multiple qquads on each hardware thread. Each qquad’s shader is called a fiber. The different fibers on a thread co-operatively switch between themselves without any OS intervention. Fibers execute in a circular queue.
對fiber的定義是:
所謂的fiber就是一段渲染16個像素的shader程序. 哪有你說的8個可變寬度的register file?
一個線程里面可以有多個fiber, fiber可以自動輪流循環切換而已.
但是可以同意你, 一個fiber等效為一個線程thread的說法. 其實準確的說 一個fiber是一個program instance.
原文認為G80是:
G80–Each SM is shared by 8 scalar processors
running up to 768 program instances (which Nvidia calls threads)
>所以4SMT是針對x86程式內的延遲設計的,所謂”短而不可預知的延遲”。所以SMT for GPGPU/x86、fiber for graphic。
基本同意
>難其實是難在TMU。
其實把tmu與core/vpu分開,對于CPU設計是有益處的.
TMU到vpu有幾百個cycles的延遲, 是合理的設計. 因為L2較大的緣故,而且larrabee的256 KB L2是本地L2–local L2. 32個L2之間還可以透過ring bus共享.
> 所以我覺得那16way SIMD效率不會低到太誇張。
肯定要比8way simd低上很多
>至於大家都看得到SMT x4,卻沒有看到vector register裡面的fiber自訂線程(8個可變寬度的register file,其實應該可以看成nvidia的8warp),由於它有指出用來隱蔽”已知長度的長延遲”,可以確定那是針對GDDR5等記憶體頻寬的延遲。
看原文Larrabee: A Many-Core x86 Architecture for Visual Computing
the setup thread issues pixels to the work threads in groups of 16 that we call a qquad.
This is hidden by computing
multiple qquads on each hardware thread. Each qquad’s shader is called a fiber. The different fibers on a thread co-operatively switch between themselves without any OS intervention. Fibers execute in a circular queue.
對fiber的定義是:
所謂的fiber就是一段渲染16個像素的shader程序. 哪有你說的8個可變寬度的register file?
一個線程里面可以有多個fiber, fiber可以自動輪流循環切換而已.
但是可以同意你, 一個fiber等效為一個線程thread的說法. 其實準確的說 一個fiber是一個program instance.
原文認為G80是:
G80–Each SM is shared by 8 scalar processors
running up to 768 program instances (which Nvidia calls threads)
>所以4SMT是針對x86程式內的延遲設計的,所謂”短而不可預知的延遲”。所以SMT for GPGPU/x86、fiber for graphic。
基本同意
>難其實是難在TMU。
其實把tmu與core/vpu分開,對于CPU設計是有益處的.
TMU到vpu有幾百個cycles的延遲, 是合理的設計. 因為L2較大的緣故,而且larrabee的256 KB L2是本地L2–local L2. 32個L2之間還可以透過ring bus共享.
>看原文Larrabee: A Many-Core x86 Architecture for Visual Computing
>
>the setup thread issues pixels to the work threads in groups of 16 that we call a qquad.
>This is hidden by computing
>multiple qquads on each hardware thread. Each qquad’s shader is called a fiber. The different fibers on a thread co-operatively switch between themselves without any OS intervention. Fibers execute in a circular queue.
>對fiber的定義是:
>所謂的fiber就是一段渲染16個像素的shader程序. 哪有你說的8個可變寬度的register file?
我指的是這個:
http://www.anandtech.com/…owdoc.aspx?i=3367&p=11
http://images.anandtech.com/…larrabeethreads.png
所以我說fiber內是可變寬度、然後最大八個fiber。
>一個線程里面可以有多個fiber, fiber可以自動輪流循環切換而已.
>但是可以同意你, 一個fiber等效為一個線程thread的說法. 其實準確的說 一個fiber是一個program instance.
本來在目前的graphic裡面,GPU就是以所謂的”SPMD”來運作的….所以這邊的thread只是用來對應到NVIDIA架構宣傳名詞的用法。大家知道就好_A_
———
>其實把tmu與core/vpu分開,對于CPU設計是有益處的.
>TMU到vpu有幾百個cycles的延遲, 是合理的設計. 因為L2較大的緣故,而且larrabee的256 KB L2是本地L2–local L2. 32個L2之間還可以透過ring bus共享.
問題不只是延遲、而是在於工作的特殊性,讀取順序及其區域性等等,這使得它非分開不可。
事實上延遲影響的是CPU core是否能維持滿載,所以TMU本身設計其實並不需要顧及”延遲”,是後端對TMU提出需求的單位,才有要吸收延遲的需求。
NVIDIA的SM為什麼會有一堆warp可以換,也是為了對應這些各式各樣的”延遲”。
此外,Larrabee的CPU core並不是以256KB L2來存放texture cache,而是有個獨立的32KB cache。
TMU內還有自己的cache…. (這也是10core版宣稱有4MB、但是256KB x 10也才2.5MB的原因,剩下的cache容量可能在TMU裡面)
>看原文Larrabee: A Many-Core x86 Architecture for Visual Computing
>
>the setup thread issues pixels to the work threads in groups of 16 that we call a qquad.
>This is hidden by computing
>multiple qquads on each hardware thread. Each qquad’s shader is called a fiber. The different fibers on a thread co-operatively switch between themselves without any OS intervention. Fibers execute in a circular queue.
>對fiber的定義是:
>所謂的fiber就是一段渲染16個像素的shader程序. 哪有你說的8個可變寬度的register file?
我指的是這個:
http://www.anandtech.com/…owdoc.aspx?i=3367&p=11
http://images.anandtech.com/…larrabeethreads.png
所以我說fiber內是可變寬度、然後最大八個fiber。
>一個線程里面可以有多個fiber, fiber可以自動輪流循環切換而已.
>但是可以同意你, 一個fiber等效為一個線程thread的說法. 其實準確的說 一個fiber是一個program instance.
本來在目前的graphic裡面,GPU就是以所謂的”SPMD”來運作的….所以這邊的thread只是用來對應到NVIDIA架構宣傳名詞的用法。大家知道就好_A_
———
>其實把tmu與core/vpu分開,對于CPU設計是有益處的.
>TMU到vpu有幾百個cycles的延遲, 是合理的設計. 因為L2較大的緣故,而且larrabee的256 KB L2是本地L2–local L2. 32個L2之間還可以透過ring bus共享.
問題不只是延遲、而是在於工作的特殊性,讀取順序及其區域性等等,這使得它非分開不可。
事實上延遲影響的是CPU core是否能維持滿載,所以TMU本身設計其實並不需要顧及”延遲”,是後端對TMU提出需求的單位,才有要吸收延遲的需求。
NVIDIA的SM為什麼會有一堆warp可以換,也是為了對應這些各式各樣的”延遲”。
此外,Larrabee的CPU core並不是以256KB L2來存放texture cache,而是有個獨立的32KB cache。
TMU內還有自己的cache…. (這也是10core版宣稱有4MB、但是256KB x 10也才2.5MB的原因,剩下的cache容量可能在TMU裡面)
>我指的是這個:
>http://www.anandtech.com/…owdoc.aspx?i=3367&p=11
>http://images.anandtech.com/…larrabeethreads.png
>所以我說fiber內是可變寬度、然後最大八個fiber。
那是anandtech亂打比方. 顯然與原文的真實含義有較大區別.
>問題不只是延遲、而是在於工作的特殊性,讀取順序及其區域性等等,這使得它非分開不可。
>事實上延遲影響的是CPU core是否能維持滿載,所以TMU本身設計其實並不需要顧及”延遲”,
>是後端對TMU提出需求的單位,才有要吸收延遲的需求。
>NVIDIA的SM為什麼會有一堆warp可以換,也是為了對應這些各式各樣的”延遲”。
顯然你這里說的難度是指tmu本身設計的難度, 而非指tmu與core協作效率. larrabee的tmu協處理器本身的性能應該是很強大的.
>此外,Larrabee的CPU core並不是以256KB L2來存放texture cache,而是有個獨立的32KB cache。
>TMU內還有自己的cache…. (這也是10core版宣稱有4MB、但是256KB x 10也才2.5MB的原因,剩下的cache容量可能在TMU裡面)
要說texture cache? G80的tmu的texture cache僅為8K,GTX280應該也是小于16K. larrabee的tmu確有32K!!
而你顯然誤解了larrabee, larrabee與GTX280區別極大,larrabee當然是靠訪問L2 來得到texture資料, larrabee是給命令到tmu,而tmu把texture cache里面的資料傳到L2. 所以才會提到L2容量,larrrabee可以提用L2來利用texture的局部性,合理編程的條件下,以后就可以透過L2快速訪問texture資料了.
而且合理編程的條件下,常用的texture constant都可以放在L1里面.
所以才會談到L2. 區別很大的.
還有10core版的,看原文,那并非larrabee,而是另一款many core試驗品. 給你算一下? 256K+32K(L1D)+32K(L1I)+32K(Texture Cache)=360K. “10核版”larrabee哪有4MB的cache? 去看看原文吧. 10核說的是什么.
>我指的是這個:
>http://www.anandtech.com/…owdoc.aspx?i=3367&p=11
>http://images.anandtech.com/…larrabeethreads.png
>所以我說fiber內是可變寬度、然後最大八個fiber。
那是anandtech亂打比方. 顯然與原文的真實含義有較大區別.
>問題不只是延遲、而是在於工作的特殊性,讀取順序及其區域性等等,這使得它非分開不可。
>事實上延遲影響的是CPU core是否能維持滿載,所以TMU本身設計其實並不需要顧及”延遲”,
>是後端對TMU提出需求的單位,才有要吸收延遲的需求。
>NVIDIA的SM為什麼會有一堆warp可以換,也是為了對應這些各式各樣的”延遲”。
顯然你這里說的難度是指tmu本身設計的難度, 而非指tmu與core協作效率. larrabee的tmu協處理器本身的性能應該是很強大的.
>此外,Larrabee的CPU core並不是以256KB L2來存放texture cache,而是有個獨立的32KB cache。
>TMU內還有自己的cache…. (這也是10core版宣稱有4MB、但是256KB x 10也才2.5MB的原因,剩下的cache容量可能在TMU裡面)
要說texture cache? G80的tmu的texture cache僅為8K,GTX280應該也是小于16K. larrabee的tmu確有32K!!
而你顯然誤解了larrabee, larrabee與GTX280區別極大,larrabee當然是靠訪問L2 來得到texture資料, larrabee是給命令到tmu,而tmu把texture cache里面的資料傳到L2. 所以才會提到L2容量,larrrabee可以提用L2來利用texture的局部性,合理編程的條件下,以后就可以透過L2快速訪問texture資料了.
而且合理編程的條件下,常用的texture constant都可以放在L1里面.
所以才會談到L2. 區別很大的.
還有10core版的,看原文,那并非larrabee,而是另一款many core試驗品. 給你算一下? 256K+32K(L1D)+32K(L1I)+32K(Texture Cache)=360K. “10核版”larrabee哪有4MB的cache? 去看看原文吧. 10核說的是什么.
或許你誤解這句話? –tmu到vpu的延遲
那是說tmu把texture資料送到16 way simd單元的延遲.
vpu是vector process unit–對應16 way simd單元. tmu本身有什么好說的? 傳統GPU該有的它larrabee都有. tmu本身肯定能設計的很強, 值得探討的就是tmu到vpu的延遲吸收技術. 除了多線程,如何利用好L2就是關鍵了,所以才談到larrabee的L2較大….., 你要跟上思路.
或許你誤解這句話? –tmu到vpu的延遲
那是說tmu把texture資料送到16 way simd單元的延遲.
vpu是vector process unit–對應16 way simd單元. tmu本身有什么好說的? 傳統GPU該有的它larrabee都有. tmu本身肯定能設計的很強, 值得探討的就是tmu到vpu的延遲吸收技術. 除了多線程,如何利用好L2就是關鍵了,所以才談到larrabee的L2較大….., 你要跟上思路.
> 那是anandtech亂打比方. 顯然與原文的真實含義有較大區別.
這張圖是從Intel的presentation直接取出來的,並不是Anandtech自己畫的,如果你有這份檔案的話,請參考page28。
fiber的規模沒有提到多大,我覺得不會變成有16 or 32組16way SIMD register set,畢竟八個這麼大的set好像有點誇張;但是這比較像是NVIDIA/ATI的GPU每個program可以使用到的register數量也是可變的,比方說DX10的規格上每個最大可以到128個register。
> 而你顯然誤解了larrabee, larrabee與GTX280區別極大,larrabee當然是靠訪問L2 來得到texture資料, larrabee是給命令到tmu,而tmu把texture cache里面的資料傳到L2. 所以才會提到L2容量,larrrabee可以提用L2來利用texture的局部性,合理編程的條件下,以后就可以透過L2快速訪問texture資料了.
呃,Larrabee CPU core不需要透過L2來”利用texture的局部性”吧。
因為運算過程中會重複使用到某些texture,所以為了避免重複讀取對bandwidth的需求,所以要做一塊texture cache;但是shader從TMU拿到的,是經過filter處理過的”texture sample”,這已經沒有”局部性”的問題了。因為這些texture局部性已經被texture cache和TMU的結構吸收掉了,只是從shader提出需求、到TMU透過存取texture產生sample送給shader中間有延遲,所以shader得自己去吸收這些延遲….
所以看到這邊,你不覺得L2和texture快速訪問一點關係都沒有了?
> 還有10core版的,看原文,那并非larrabee,而是另一款many core試驗品. 給你算一下? 256K+32K(L1D)+32K(L1I)+32K(Texture Cache)=360K. “10核版”larrabee哪有4MB的cache? 去看看原文吧. 10核說的是什么.
原文是
since the wide VPU supports fused multiply-add but SSE doesn’t. These in-order cores are not Larrabee, but are similar.
那不是Larrabee的產品沒錯,而是另外一個實驗用的核心,地位類似當初的80core;因為這個核心的ISA有FMAD的關係,所以不是真正的Larrabee ISA,他只是在想”我到底可以透過這些設計方法大概做到多大的密度”,但是實際上關聯並不大啦。
> 或許你誤解這句話? –tmu到vpu的延遲
> 那是說tmu把texture資料送到16 way simd單元的延遲.
> vpu是vector process unit–對應16 way simd單元. tmu本身有什么好說的? 傳統GPU該有的它larrabee都有. tmu本身肯定能設計的很強, 值得探討的就是tmu到vpu的延遲吸收技術. 除了多線程,如何利用好L2就是關鍵了,所以才談到larrabee的L2較大…..
我上面已經說了,Larrabee的L2和texture本身的locality我覺得沒什麼關聯….
但是Larrabee的cache和延遲吸收應該是有非常大的關係,這邊關聯比較大的是如何用cache去做出類似register file般的結構,比方說Larrabee有企圖拿32KB L1來當成temp register代用品,所以做了一個1cycle latency的L1,這裡應是想彌補x86原有指令集與結構在register數量上的不足,不然的話128個32bit register相對於x86仍然是很龐大的數量。
由於限制於x86 ISA的關係,它很難在兩全的情況下提供很好的延遲隱蔽,但是這也有另一個前提是電晶體成本的限制,偏偏這方面Intel除了對成本的注重之外,其實可用的預算並不低。
> 你要跟上思路.
我可以理解您想表達的內容,但是用貶低的語氣並以用詞來爭奪發言主導權並無助於任何討論,畢竟個人沒有必要去”迎合”您的”思路”,或許我們之間用詞有點差異所以需要磨合,但是應該是個平等的討論地位。
> 那是anandtech亂打比方. 顯然與原文的真實含義有較大區別.
這張圖是從Intel的presentation直接取出來的,並不是Anandtech自己畫的,如果你有這份檔案的話,請參考page28。
fiber的規模沒有提到多大,我覺得不會變成有16 or 32組16way SIMD register set,畢竟八個這麼大的set好像有點誇張;但是這比較像是NVIDIA/ATI的GPU每個program可以使用到的register數量也是可變的,比方說DX10的規格上每個最大可以到128個register。
> 而你顯然誤解了larrabee, larrabee與GTX280區別極大,larrabee當然是靠訪問L2 來得到texture資料, larrabee是給命令到tmu,而tmu把texture cache里面的資料傳到L2. 所以才會提到L2容量,larrrabee可以提用L2來利用texture的局部性,合理編程的條件下,以后就可以透過L2快速訪問texture資料了.
呃,Larrabee CPU core不需要透過L2來”利用texture的局部性”吧。
因為運算過程中會重複使用到某些texture,所以為了避免重複讀取對bandwidth的需求,所以要做一塊texture cache;但是shader從TMU拿到的,是經過filter處理過的”texture sample”,這已經沒有”局部性”的問題了。因為這些texture局部性已經被texture cache和TMU的結構吸收掉了,只是從shader提出需求、到TMU透過存取texture產生sample送給shader中間有延遲,所以shader得自己去吸收這些延遲….
所以看到這邊,你不覺得L2和texture快速訪問一點關係都沒有了?
> 還有10core版的,看原文,那并非larrabee,而是另一款many core試驗品. 給你算一下? 256K+32K(L1D)+32K(L1I)+32K(Texture Cache)=360K. “10核版”larrabee哪有4MB的cache? 去看看原文吧. 10核說的是什么.
原文是
since the wide VPU supports fused multiply-add but SSE doesn’t. These in-order cores are not Larrabee, but are similar.
那不是Larrabee的產品沒錯,而是另外一個實驗用的核心,地位類似當初的80core;因為這個核心的ISA有FMAD的關係,所以不是真正的Larrabee ISA,他只是在想”我到底可以透過這些設計方法大概做到多大的密度”,但是實際上關聯並不大啦。
> 或許你誤解這句話? –tmu到vpu的延遲
> 那是說tmu把texture資料送到16 way simd單元的延遲.
> vpu是vector process unit–對應16 way simd單元. tmu本身有什么好說的? 傳統GPU該有的它larrabee都有. tmu本身肯定能設計的很強, 值得探討的就是tmu到vpu的延遲吸收技術. 除了多線程,如何利用好L2就是關鍵了,所以才談到larrabee的L2較大…..
我上面已經說了,Larrabee的L2和texture本身的locality我覺得沒什麼關聯….
但是Larrabee的cache和延遲吸收應該是有非常大的關係,這邊關聯比較大的是如何用cache去做出類似register file般的結構,比方說Larrabee有企圖拿32KB L1來當成temp register代用品,所以做了一個1cycle latency的L1,這裡應是想彌補x86原有指令集與結構在register數量上的不足,不然的話128個32bit register相對於x86仍然是很龐大的數量。
由於限制於x86 ISA的關係,它很難在兩全的情況下提供很好的延遲隱蔽,但是這也有另一個前提是電晶體成本的限制,偏偏這方面Intel除了對成本的注重之外,其實可用的預算並不低。
> 你要跟上思路.
我可以理解您想表達的內容,但是用貶低的語氣並以用詞來爭奪發言主導權並無助於任何討論,畢竟個人沒有必要去”迎合”您的”思路”,或許我們之間用詞有點差異所以需要磨合,但是應該是個平等的討論地位。
>這張圖是從Intel的presentation直接取出來的,並不是Anandtech自己畫的,如果你有這份檔案的話,請參考page28。
圖并没有什么,而是Anandtech乱解读.
>呃,Larrabee CPU core不需要透過L2來”利用texture的局部性”吧。
請看原文
Cores pass commands to the texture units through the L2 cache and receive results the same way.
顯然larrabee的tmu與GTX280有極大差別. L2 cache是處理后的texture的存放處. tmu的texture cache應該是存放原/或壓縮texture等, 而L2 cache是存放filter/或解壓后的texture. vpu是要到L2 cache來訪問texture資料的. 所以larrabee合理編程利用L2 cache來吸收延遲的模式, 確實是傳統GPU難以想象的. 例如, 合理編程條件下,有的場景情況下,larrabee僅需要發出一次fetch texture命令,今后就可以多次到L2取得解壓/或過濾后的texture,而無需tmu多次重復過濾的動作,也無需多次耗用ringbus的傳輸帶寬,無需幾百cycles的延遲. 等于是節省tmu計算與ringbus頻寬資源, 而且local L2的頻寬是很大的, 有極大的放大作用, 假定是L2頻寬是256bit/cycles,32個L2@2GHz的峰值就是32*2*32約2000GB/cycles.
>比方說Larrabee有企圖拿32KB L1來當成temp register代用品,所以做了一個1cycle latency的L1,
>這裡應是想彌補x86原有指令集與結構在register數量上的不足,不然的話128個32bit register相對於x86仍然是很龐大的數量。
談到isa, 原文指出, 幾乎是vpu所有的vector計算指令,都可以使用[memory],這點很有類似x86. larrabee vpu isa是一種CISC指令. 例如,
vreg0=vreg1-[memory]
larrabee可以單指令完成.
一般類似risc的指令需要兩個指令,一個load [memory]指令,一個vector減法指令.
vpu的CISC isa是有點特色. 但是應該還是問題多多.
>我可以理解您想表達的內容,但是用貶低的語氣並以用詞來爭奪發言主導權並無助於任何討論,畢竟個人沒有必要去”迎合”您的”思路”,或許我們之間用詞有點差異所以需要磨合,但是應該是個平等的討論地位。
你討論的態度值得欣賞,也較為大度. 你對GPU確實是要相對更了解. larrabee的原文,有些地方你卻沒有細看. 其很多實現方式會有較大區別.
>這張圖是從Intel的presentation直接取出來的,並不是Anandtech自己畫的,如果你有這份檔案的話,請參考page28。
圖并没有什么,而是Anandtech乱解读.
>呃,Larrabee CPU core不需要透過L2來”利用texture的局部性”吧。
請看原文
Cores pass commands to the texture units through the L2 cache and receive results the same way.
顯然larrabee的tmu與GTX280有極大差別. L2 cache是處理后的texture的存放處. tmu的texture cache應該是存放原/或壓縮texture等, 而L2 cache是存放filter/或解壓后的texture. vpu是要到L2 cache來訪問texture資料的. 所以larrabee合理編程利用L2 cache來吸收延遲的模式, 確實是傳統GPU難以想象的. 例如, 合理編程條件下,有的場景情況下,larrabee僅需要發出一次fetch texture命令,今后就可以多次到L2取得解壓/或過濾后的texture,而無需tmu多次重復過濾的動作,也無需多次耗用ringbus的傳輸帶寬,無需幾百cycles的延遲. 等于是節省tmu計算與ringbus頻寬資源, 而且local L2的頻寬是很大的, 有極大的放大作用, 假定是L2頻寬是256bit/cycles,32個L2@2GHz的峰值就是32*2*32約2000GB/cycles.
>比方說Larrabee有企圖拿32KB L1來當成temp register代用品,所以做了一個1cycle latency的L1,
>這裡應是想彌補x86原有指令集與結構在register數量上的不足,不然的話128個32bit register相對於x86仍然是很龐大的數量。
談到isa, 原文指出, 幾乎是vpu所有的vector計算指令,都可以使用[memory],這點很有類似x86. larrabee vpu isa是一種CISC指令. 例如,
vreg0=vreg1-[memory]
larrabee可以單指令完成.
一般類似risc的指令需要兩個指令,一個load [memory]指令,一個vector減法指令.
vpu的CISC isa是有點特色. 但是應該還是問題多多.
>我可以理解您想表達的內容,但是用貶低的語氣並以用詞來爭奪發言主導權並無助於任何討論,畢竟個人沒有必要去”迎合”您的”思路”,或許我們之間用詞有點差異所以需要磨合,但是應該是個平等的討論地位。
你討論的態度值得欣賞,也較為大度. 你對GPU確實是要相對更了解. larrabee的原文,有些地方你卻沒有細看. 其很多實現方式會有較大區別.
>由於Larrabee在TMU這部分已經有電晶體投資,現在Larrabee和GPU主要的性能差,就在延遲吸收、與ROP軟體化之後的性能差距。
關于Rasteration/ROP等軟體化, 有點意見想說. 應該是larrabee的load平衡相當差, 有很多時候有的核心是會有出現空閑的計算資源, 然后被拿來計算Rasteration/ROP.
larrabee的軟體渲染器software render, 千方百計的制造或尋找可以亂序執行out of order的計算任務, 提高并行化計算程度.
應該還是很難實現load平衡, 運氣好的話, 空閑資源被大量回收進行Rasteration/ROP等軟體化– 企圖out of order化的software render卻還要受到相容性 Compatibility的限制.
是很尷尬的調度– load失衡會導致局部資源空閑,而空閑資源卻可以拿來計算Rasteration/ROP等. 還是先出現低效的場合,然后減少點低效場合的代價.
>由於Larrabee在TMU這部分已經有電晶體投資,現在Larrabee和GPU主要的性能差,就在延遲吸收、與ROP軟體化之後的性能差距。
關于Rasteration/ROP等軟體化, 有點意見想說. 應該是larrabee的load平衡相當差, 有很多時候有的核心是會有出現空閑的計算資源, 然后被拿來計算Rasteration/ROP.
larrabee的軟體渲染器software render, 千方百計的制造或尋找可以亂序執行out of order的計算任務, 提高并行化計算程度.
應該還是很難實現load平衡, 運氣好的話, 空閑資源被大量回收進行Rasteration/ROP等軟體化– 企圖out of order化的software render卻還要受到相容性 Compatibility的限制.
是很尷尬的調度– load失衡會導致局部資源空閑,而空閑資源卻可以拿來計算Rasteration/ROP等. 還是先出現低效的場合,然后減少點低效場合的代價.
> 顯然larrabee的tmu與GTX280有極大差別. L2 cache是處理后的texture的存放處. tmu的texture cache應該是存放原/或壓縮texture等, 而L2 cache是存放filter/或解壓后的texture. vpu是要到L2 cache來訪問texture資料的.所以larrabee合理編程利用L2 cache來吸收延遲的模式, 確實是傳統GPU難以想象的. 例如, 合理編程條件下,有的場景情況下,larrabee僅需要發出一次fetch texture命令,今后就可以多次到L2取得解壓/或過濾后的texture,而無需tmu多次重復過濾的動作,也無需多次耗用ringbus的傳輸帶寬,無需幾百cycles的延遲.等于是節省tmu計算與ringbus頻寬資源, 而且local L2的頻寬是很大的, 有極大的放大作用, 假定是L2頻寬是256bit/cycles,32個L2@2GHz的峰值就是32*2*32約2000GB/cycles.
以我對GPU的理解來說,目前大部分的TMU仍然是存放處理前的texture,filtered過的sample是直接送給shader,至於shader怎麼處理TMU是不過問的。
這樣說好了,通常GPU shader是把sample直接扔進register,但上面都說過Larrabee是拿cache subsystem來模擬成register file,L2 cache裡面甚至還放了tile,是一個軟體排程的unified storage space,你不覺得這時候說texture存取模式不同有點怪?
與其說是texture存取模式變換,倒不如說是軟體如果控制得宜的話,就變成可以在shader unit(這時候是有cache的CPU core)裡面存放”超級多的warp”(以單一TPC有64KB的GT200、以及unit較多卻同為256KB的RV770而言);而且事實上本來texture存取行為本來就不會重複,每個sample事實上都是獨一無二的(只是因為texture sampling行為,可能會在類似位置取得texel重複使用),這邊的問題單純只是texture unit離shader較遠或是較近而已。
今天差異比較大的應該是透過binning之類的render method在節省頻寬,TMU部分反而是差異不大的部分,也因為”(即使改成software rendering)仍然沒有什麼可以變化的部分,目前的方法效率很高”,所以才要實作TMU,這是我的想法。
所以我還是同樣的理由,我覺得在TMU行為上其實沒有差異….
>關于Rasteration/ROP等軟體化, 有點意見想說. 應該是larrabee的load平衡相當差, 有很多時候有的核心是會有出現空閑的計算資源, 然后被拿來計算Rasteration/ROP.
>larrabee的軟體渲染器software render, 千方百計的制造或尋找可以亂序執行out of order的計算任務, 提高并行化計算程度.
>應該還是很難實現load平衡, 運氣好的話, 空閑資源被大量回收進行Rasteration/ROP等軟體化– 企圖out of order化的software render卻還要受到相容性 Compatibility的限制.
>是很尷尬的調度– load失衡會導致局部資源空閑,而空閑資源卻可以拿來計算Rasteration/ROP等. 還是先出現低效的場合,然后減少點低效場合的代價.
為什麼Larrabee要尋找可以”OOOE”的task?它本身的core並不是OOOE啊。
而且hardwired的ROP其實閒置的機會更大….沒工作就是沒在運作。
我覺得其實Larrabee透過software rendering的主要目的是為了迴避GPU vendor在ROP上面已經有的大量patent問題,同時可以在GPGPU task上面避免ROP閒置。
> 顯然larrabee的tmu與GTX280有極大差別. L2 cache是處理后的texture的存放處. tmu的texture cache應該是存放原/或壓縮texture等, 而L2 cache是存放filter/或解壓后的texture. vpu是要到L2 cache來訪問texture資料的.所以larrabee合理編程利用L2 cache來吸收延遲的模式, 確實是傳統GPU難以想象的. 例如, 合理編程條件下,有的場景情況下,larrabee僅需要發出一次fetch texture命令,今后就可以多次到L2取得解壓/或過濾后的texture,而無需tmu多次重復過濾的動作,也無需多次耗用ringbus的傳輸帶寬,無需幾百cycles的延遲.等于是節省tmu計算與ringbus頻寬資源, 而且local L2的頻寬是很大的, 有極大的放大作用, 假定是L2頻寬是256bit/cycles,32個L2@2GHz的峰值就是32*2*32約2000GB/cycles.
以我對GPU的理解來說,目前大部分的TMU仍然是存放處理前的texture,filtered過的sample是直接送給shader,至於shader怎麼處理TMU是不過問的。
這樣說好了,通常GPU shader是把sample直接扔進register,但上面都說過Larrabee是拿cache subsystem來模擬成register file,L2 cache裡面甚至還放了tile,是一個軟體排程的unified storage space,你不覺得這時候說texture存取模式不同有點怪?
與其說是texture存取模式變換,倒不如說是軟體如果控制得宜的話,就變成可以在shader unit(這時候是有cache的CPU core)裡面存放”超級多的warp”(以單一TPC有64KB的GT200、以及unit較多卻同為256KB的RV770而言);而且事實上本來texture存取行為本來就不會重複,每個sample事實上都是獨一無二的(只是因為texture sampling行為,可能會在類似位置取得texel重複使用),這邊的問題單純只是texture unit離shader較遠或是較近而已。
今天差異比較大的應該是透過binning之類的render method在節省頻寬,TMU部分反而是差異不大的部分,也因為”(即使改成software rendering)仍然沒有什麼可以變化的部分,目前的方法效率很高”,所以才要實作TMU,這是我的想法。
所以我還是同樣的理由,我覺得在TMU行為上其實沒有差異….
>關于Rasteration/ROP等軟體化, 有點意見想說. 應該是larrabee的load平衡相當差, 有很多時候有的核心是會有出現空閑的計算資源, 然后被拿來計算Rasteration/ROP.
>larrabee的軟體渲染器software render, 千方百計的制造或尋找可以亂序執行out of order的計算任務, 提高并行化計算程度.
>應該還是很難實現load平衡, 運氣好的話, 空閑資源被大量回收進行Rasteration/ROP等軟體化– 企圖out of order化的software render卻還要受到相容性 Compatibility的限制.
>是很尷尬的調度– load失衡會導致局部資源空閑,而空閑資源卻可以拿來計算Rasteration/ROP等. 還是先出現低效的場合,然后減少點低效場合的代價.
為什麼Larrabee要尋找可以”OOOE”的task?它本身的core並不是OOOE啊。
而且hardwired的ROP其實閒置的機會更大….沒工作就是沒在運作。
我覺得其實Larrabee透過software rendering的主要目的是為了迴避GPU vendor在ROP上面已經有的大量patent問題,同時可以在GPGPU task上面避免ROP閒置。
>這樣說好了,通常GPU shader是把sample直接扔進register,但上面都說過Larrabee是拿cache subsystem來模擬成register file,L2 cache裡面甚至還放了tile,是一個軟體排程的unified storage space,你不覺得這時候說texture存取模式不同有點怪?
根據你的看法, 是說相當于larrabee可以有超多的寄存器(而延遲較大)來接收過濾后的texture而已.
>而且事實上本來texture存取行為本來就不會重複,每個sample事實上都是獨一無二的(只是因為texture sampling行為,可能會在類似位置取得texel重複使用),這邊的問題單純只是texture unit離shader較遠或是較近而已。
如果沒有理解錯的話? 你是說經過tmu過濾(filter)后的texture,其局部性/區域性很低,其實reuse的概率極低. 并非存在有效的區域性.
跨fiber的reuse的可能性是否存在呢?
如果存在reuse的可能, 設想一下reuse的方式:
既然是larrabee給命令到tmu,那應該是必須指定tmu把過濾后的texture寫到某個具體的地址address里, 由L2映射(map)到某個實際cache line里. vpu去讀取L2的texture資料的時候,如果地址address相同以及返回有效位時, 就可以use資料. 而其他fiber要reuse那些texture資料,也可以使用相同的地址address去訪問.
你要強調的是,larrabee的渲染模式,依然是很難存在關于過濾后的texture的reuse機會的. 是吧?
>為什麼Larrabee要尋找可以”OOOE”的task?它本身的core並不是OOOE啊。
>而且hardwired的ROP其實閒置的機會更大….沒工作就是沒在運作。
任務級的OOO與指令級OOO是有區別的。 你理解有錯位的地方. 一個是軟件層OOO, 一個是硬件指令級OOO. 循序CORE完全可以來實現軟件層的OOO.
軟件層上的OOO一般是為了多核/多線程并行最大化, 你可以參考原文
an immediate-mode renderer doesn’t have as many ways to process pixels and primitives out of order.
你別看成指令級OOO啊? 那是大錯位. 還是看看原文吧.
光柵/ROP很多時候是用load非平衡的空閑核心來計算的. 而一般ROP是需要等到最后處理. larrabee的Software Render是使用編程盡可能創造或尋找亂序執行out of order的計算機會, 實現并行最大化. 可能是內部是多幀out of order? 提交的時候是按api循序? 誰知道了?Software太靈活了, 或許還有好幾種備用的Software Render模式? 一切為了out of order最大化.
>這樣說好了,通常GPU shader是把sample直接扔進register,但上面都說過Larrabee是拿cache subsystem來模擬成register file,L2 cache裡面甚至還放了tile,是一個軟體排程的unified storage space,你不覺得這時候說texture存取模式不同有點怪?
根據你的看法, 是說相當于larrabee可以有超多的寄存器(而延遲較大)來接收過濾后的texture而已.
>而且事實上本來texture存取行為本來就不會重複,每個sample事實上都是獨一無二的(只是因為texture sampling行為,可能會在類似位置取得texel重複使用),這邊的問題單純只是texture unit離shader較遠或是較近而已。
如果沒有理解錯的話? 你是說經過tmu過濾(filter)后的texture,其局部性/區域性很低,其實reuse的概率極低. 并非存在有效的區域性.
跨fiber的reuse的可能性是否存在呢?
如果存在reuse的可能, 設想一下reuse的方式:
既然是larrabee給命令到tmu,那應該是必須指定tmu把過濾后的texture寫到某個具體的地址address里, 由L2映射(map)到某個實際cache line里. vpu去讀取L2的texture資料的時候,如果地址address相同以及返回有效位時, 就可以use資料. 而其他fiber要reuse那些texture資料,也可以使用相同的地址address去訪問.
你要強調的是,larrabee的渲染模式,依然是很難存在關于過濾后的texture的reuse機會的. 是吧?
>為什麼Larrabee要尋找可以”OOOE”的task?它本身的core並不是OOOE啊。
>而且hardwired的ROP其實閒置的機會更大….沒工作就是沒在運作。
任務級的OOO與指令級OOO是有區別的。 你理解有錯位的地方. 一個是軟件層OOO, 一個是硬件指令級OOO. 循序CORE完全可以來實現軟件層的OOO.
軟件層上的OOO一般是為了多核/多線程并行最大化, 你可以參考原文
an immediate-mode renderer doesn’t have as many ways to process pixels and primitives out of order.
你別看成指令級OOO啊? 那是大錯位. 還是看看原文吧.
光柵/ROP很多時候是用load非平衡的空閑核心來計算的. 而一般ROP是需要等到最后處理. larrabee的Software Render是使用編程盡可能創造或尋找亂序執行out of order的計算機會, 實現并行最大化. 可能是內部是多幀out of order? 提交的時候是按api循序? 誰知道了?Software太靈活了, 或許還有好幾種備用的Software Render模式? 一切為了out of order最大化.
>>Cores pass commands to the texture
>>units through the L2 cache and receive >>results the same way.
這應該只是說CPU把讀取texel的request,
丟到L2 cache的一個command list,
而TMU依序處理這些工作,並將結果filtered texel丟到L2的cache的一個位置等cpu來存取.
說明CPU和TMU的資料傳輸都透過L2 cache進行罷了.
CPU無法直接發放命令給TMU,而是透過L2.
TMU也無直接把資料傳給CPU的register,而是透過L2.
TMU的32KB cache存放的是原始的texel data.
TMU做filtering後的texel則是傳到L2待取.
一般GPU的TMU和Shader core很密切,TMU可以把資料放到Shader core可以直接動用的register file.
因為每個GPU架構都是特製化的設計,才能這樣做.
而Larrabee畢竟是CPU core延申而來.
只是在內部bus上多了TMU.
他的TMU比較像是專門處理材質的coprocessor,
他的TMU跟CPU的距離比較遠,兩者是透過L2做協同.
L2不是用來利用texture的局部性,而是不同core
交換資料的地方.
其實texture cache 8k還是32k對遊戲來說
效能是沒有很大差別的.
因為材質太大了,除了相鄰pixel會共用幾個
texel sample外, 一般來說,不同位置的Pixel
不共用texel.
材質都是好幾MB了,而且Pixel shader用到的材質
往往不只一張,所以除非Tex cache大到幾MB的大小.
否則多幾十KB根本沒差別.
所以GPU不能靠加大tex cache來改善latency,
而是靠很多的thread把發放需求和實際取用,
隔了數百cycle,使latency對效能沒有影響.
所以texture cache只要夠放附近幾個pixel能用到的
texel sample就可以了,
所以GPU texture cache 的成長很緩慢.
除非導入新的texel格式,例如FP16,FP32…
才需要增加tex cache的容量.
Larrabee運作跟out of order應該無關.
模擬ROP:只是某些core某些thread用軟體指定做ROP的工作罷了….ROP其實不需要多少計算力,它是需要大量頻寬的工作.
>>Cores pass commands to the texture
>>units through the L2 cache and receive >>results the same way.
這應該只是說CPU把讀取texel的request,
丟到L2 cache的一個command list,
而TMU依序處理這些工作,並將結果filtered texel丟到L2的cache的一個位置等cpu來存取.
說明CPU和TMU的資料傳輸都透過L2 cache進行罷了.
CPU無法直接發放命令給TMU,而是透過L2.
TMU也無直接把資料傳給CPU的register,而是透過L2.
TMU的32KB cache存放的是原始的texel data.
TMU做filtering後的texel則是傳到L2待取.
一般GPU的TMU和Shader core很密切,TMU可以把資料放到Shader core可以直接動用的register file.
因為每個GPU架構都是特製化的設計,才能這樣做.
而Larrabee畢竟是CPU core延申而來.
只是在內部bus上多了TMU.
他的TMU比較像是專門處理材質的coprocessor,
他的TMU跟CPU的距離比較遠,兩者是透過L2做協同.
L2不是用來利用texture的局部性,而是不同core
交換資料的地方.
其實texture cache 8k還是32k對遊戲來說
效能是沒有很大差別的.
因為材質太大了,除了相鄰pixel會共用幾個
texel sample外, 一般來說,不同位置的Pixel
不共用texel.
材質都是好幾MB了,而且Pixel shader用到的材質
往往不只一張,所以除非Tex cache大到幾MB的大小.
否則多幾十KB根本沒差別.
所以GPU不能靠加大tex cache來改善latency,
而是靠很多的thread把發放需求和實際取用,
隔了數百cycle,使latency對效能沒有影響.
所以texture cache只要夠放附近幾個pixel能用到的
texel sample就可以了,
所以GPU texture cache 的成長很緩慢.
除非導入新的texel格式,例如FP16,FP32…
才需要增加tex cache的容量.
Larrabee運作跟out of order應該無關.
模擬ROP:只是某些core某些thread用軟體指定做ROP的工作罷了….ROP其實不需要多少計算力,它是需要大量頻寬的工作.
請教一下,以下是否是larrabee一些弱點呢?
larrabee的tmu離shader太遠了. 有幾百個cycles的延遲.
而GTX280的tmu到shader的延遲應該是小得多. 延遲上有大優勢.
還有頻寬問題, larrabee的內存控制器MC與L2與tmu都掛在ring bus上. 有點搞笑的是tmu向L2送sample都還要占用ring bus, 相當于耗費全局頻寬.
太擁擠了.
而GTX280與tmu之間應該有本地直接通道,哪里會占用全局頻寬?
線程數太少,一個核心3*8才24個線程用于shader,難于高效吸收延遲
isa也比GPU的要低效.
還有軟體實現光柵/rop等開銷.
————–
如此低效larrabee,效能要遠遠于GTX280. 可能是1/4,1/6,或許是1/10以下.
請教一下,以下是否是larrabee一些弱點呢?
larrabee的tmu離shader太遠了. 有幾百個cycles的延遲.
而GTX280的tmu到shader的延遲應該是小得多. 延遲上有大優勢.
還有頻寬問題, larrabee的內存控制器MC與L2與tmu都掛在ring bus上. 有點搞笑的是tmu向L2送sample都還要占用ring bus, 相當于耗費全局頻寬.
太擁擠了.
而GTX280與tmu之間應該有本地直接通道,哪里會占用全局頻寬?
線程數太少,一個核心3*8才24個線程用于shader,難于高效吸收延遲
isa也比GPU的要低效.
還有軟體實現光柵/rop等開銷.
————–
如此低效larrabee,效能要遠遠于GTX280. 可能是1/4,1/6,或許是1/10以下.
經過TMU過濾的texture,
對shader unit來說就只是一個color值而已.
沒有任何局部性/區域性,也沒有reuse的概念.
因為你不會存取同一個位置.
就算是存取相鄰近位置,TMU也是要重新做filtering.
每次的color值都是獨一無二的.
即使不同core去存取L2的filtering texcolor.
它也無法判斷是否是同一個位置.
因為不知道材質UV座標是否相同….
所以沒有共用性可言.
有局部性/區域性的是texture cache從DRAM讀取texel的時候,這些texel在filtering時常會被reuse.
(前提是位置要相鄰)
這部份TMU和tex cache解決掉了
經過TMU過濾的texture,
對shader unit來說就只是一個color值而已.
沒有任何局部性/區域性,也沒有reuse的概念.
因為你不會存取同一個位置.
就算是存取相鄰近位置,TMU也是要重新做filtering.
每次的color值都是獨一無二的.
即使不同core去存取L2的filtering texcolor.
它也無法判斷是否是同一個位置.
因為不知道材質UV座標是否相同….
所以沒有共用性可言.
有局部性/區域性的是texture cache從DRAM讀取texel的時候,這些texel在filtering時常會被reuse.
(前提是位置要相鄰)
這部份TMU和tex cache解決掉了
>>larrabee的tmu離shader太遠了.
>>有幾百個cycles的延遲.
不只是larrabee.
其實GT280也是存取材質常常有數百cycle的延遲.
TMU距離遠不是延遲主要原因,外部記憶體就是這麼慢
,只要tex cache miss了….即始是像NV40那種
TMU/PS緊密包在一起也是有數百cycle的延遲.
所以不管是哪個架構,TMU的latency都是必然的, shader unit要自己想辦法吸收那個數百cycle的延遲
GT280是透過大量的thread切換,每個thread處理數十個pixel,我們已知道效果很明確,能吸收數百cycle延遲.
下一代45nm的GPU只會更強.
larrabee是4個thread再加上效果不確定的fiber.
問題只是fiber的數量與功效夠不夠.
畢竟仍是假設性濃厚的硬體,只能用猜的.
>>larrabee的tmu離shader太遠了.
>>有幾百個cycles的延遲.
不只是larrabee.
其實GT280也是存取材質常常有數百cycle的延遲.
TMU距離遠不是延遲主要原因,外部記憶體就是這麼慢
,只要tex cache miss了….即始是像NV40那種
TMU/PS緊密包在一起也是有數百cycle的延遲.
所以不管是哪個架構,TMU的latency都是必然的, shader unit要自己想辦法吸收那個數百cycle的延遲
GT280是透過大量的thread切換,每個thread處理數十個pixel,我們已知道效果很明確,能吸收數百cycle延遲.
下一代45nm的GPU只會更強.
larrabee是4個thread再加上效果不確定的fiber.
問題只是fiber的數量與功效夠不夠.
畢竟仍是假設性濃厚的硬體,只能用猜的.
to WaffenSS兄:
> larrabee是4個thread再加上效果不確定的fiber.
> 問題只是fiber的數量與功效夠不夠.
> 畢竟仍是假設性濃厚的硬體,只能用猜的.
嗯,我覺得延遲吸收這邊因為全靠軟體 + cache子系統硬幹太不保險是個重點,但是Intel手上也只有這個手段所以沒辦法。
畢竟要學類似N/A那種multi-bank register file大概都會扯到既有專利,所以intel他們是為了把手上的資源做最大效用發揮所以選擇這個途徑。
不過我認為Intel技術上能提供的cache頻寬非常大,這點對ROP operation算是有幫助,畢竟ROP現在運算需求逐年下降….
to WaffenSS兄:
> larrabee是4個thread再加上效果不確定的fiber.
> 問題只是fiber的數量與功效夠不夠.
> 畢竟仍是假設性濃厚的硬體,只能用猜的.
嗯,我覺得延遲吸收這邊因為全靠軟體 + cache子系統硬幹太不保險是個重點,但是Intel手上也只有這個手段所以沒辦法。
畢竟要學類似N/A那種multi-bank register file大概都會扯到既有專利,所以intel他們是為了把手上的資源做最大效用發揮所以選擇這個途徑。
不過我認為Intel技術上能提供的cache頻寬非常大,這點對ROP operation算是有幫助,畢竟ROP現在運算需求逐年下降….
to 見無:
> 根據你的看法, 是說相當于larrabee可以有超多的寄存器(而延遲較大)來接收過濾后的texture而已.
> 你要強調的是,larrabee的渲染模式,依然是很難存在關于過濾后的texture的reuse機會的. 是吧?
filtered後的texture已經不是texture,而是 texture sample,或者是一個color,所以當然是每個pixel需要都得重算,沒有re-use的機會….pixel shader能快就是因為不考慮re-use、不考慮memory access所以才能快的。
但是即使如此,我還是沒看過software renderer在衝OOOE的…. 畢竟一個frame還是要全部完成了才能送出來。
而每個pixel除非有關連性,才會說誰要先做快一點會有差,目前來說都沒有這種能力所以我沒想過該怎麼做;不過如果今天有人就是要寫個要用到旁邊pixel的z-value這種怪shader的話也沒辦法,這種時候就是Larrabee會比較靈活….
不然的話我會覺得DX11那樣,在最後補一個compute shader stage專門來做post-processing的會比較適當,每個stage都有比較乾淨的加速能力,也比較能夠平行化,功能做得太靈活可能就會變成得要serialize,那就會減弱平行能力了。
> 任務級的OOO與指令級OOO是有區別的。 你理解有錯位的地方. 一個是軟件層OOO, 一個是硬件指令級OOO. 循序CORE完全可以來實現軟件層的OOO.
task level OOOE?你是不是指的是GPU的inter-warp OOOE?
那是現在這種時代的GPU理所當然應該得做到的啊。不然競爭力不夠的。
不然可能要再深入解釋一下。
warp內的OOOE的話似乎意義不大,不過先前RacingPHT兄在PIL提過另外一種別的說法,我不知道你指的是不是這種OOOE。:
http://we.pcinlife.com/…romuid=12048#pid17960419
>請教一下,以下是否是larrabee一些弱點呢?
>larrabee的tmu離shader太遠了. 有幾百個cycles的延遲.
>而GTX280的tmu到shader的延遲應該是小得多. 延遲上有大優勢.
可是這樣的話,GT200也因為shader和TMU直接固接連結,所以每個shader其實都只能用”那個TMU”….XD
這點RV770也一樣。
>還有頻寬問題, larrabee的內存控制器MC與L2與tmu都掛在ring bus上. 有點搞笑的是tmu向L2送sample都還要占用ring bus, 相當于耗費全局頻寬.
>太擁擠了.
老實說其實一樣啦。以G8x/G9x/GT200,還有RV770,從ROP的texture L2 cache到TMU的texture L1 cache中間的傳輸都是耗用所謂的”全局頻寬”,就是TPC/ROP等單位大家一起共用的一組internal bus(已知應該是crossbar)。
上面說的”TMU和shader固接連結”,就是靠bus來改善存取L2 texture cache,來讓它可以有效率地存取很多個不同位置的texture,所以L1 for sample(filtering),L2 for memory latency,空間和用途都是不太一樣的。
目前這一代DX10 GPU(RV770)都是讓shader unit以整個bank為單位,用time multiplx來share一個TMU,也就是一個bank擺一個(可能是G8x/RV770那樣4個一組、或者是G84~G9x/GT200以後的8 個一組),然後大家一起瓜分,這時候就有所謂的專用bus,filter過的東西也可以很快地傳給shader unit。然後要讀取的東西在定址後則經由texture cache L1/L2/memory controller分層從外面讀回來,這邊延遲很長但是沒關係,shader unit本身具備multi thread能力所以經得起等。
而Larrabee的話雖然說是ring bus,看起來效率比較低,不過它也是有固定比例(16core分 512bit),所以每個core相當於還是有一定程度的固定頻寬可用,那其實就沒差了;256KB L2 cache要看他們自己如何有效率地分配,而且這個機制也沒有驗證過,不知道能不能用。
總之bus的效率比較差,可以省下一些cost;但是同時增加的延遲就得準備更多的thread去吸收,結果就看哪邊成本比較高,來省哪邊….Intel顯然是cache做得太有自信了,所以大概覺得cache都可以搞定;當然真的搞定了還是得拍拍手就是。_A_
to 見無:
> 根據你的看法, 是說相當于larrabee可以有超多的寄存器(而延遲較大)來接收過濾后的texture而已.
> 你要強調的是,larrabee的渲染模式,依然是很難存在關于過濾后的texture的reuse機會的. 是吧?
filtered後的texture已經不是texture,而是 texture sample,或者是一個color,所以當然是每個pixel需要都得重算,沒有re-use的機會….pixel shader能快就是因為不考慮re-use、不考慮memory access所以才能快的。
但是即使如此,我還是沒看過software renderer在衝OOOE的…. 畢竟一個frame還是要全部完成了才能送出來。
而每個pixel除非有關連性,才會說誰要先做快一點會有差,目前來說都沒有這種能力所以我沒想過該怎麼做;不過如果今天有人就是要寫個要用到旁邊pixel的z-value這種怪shader的話也沒辦法,這種時候就是Larrabee會比較靈活….
不然的話我會覺得DX11那樣,在最後補一個compute shader stage專門來做post-processing的會比較適當,每個stage都有比較乾淨的加速能力,也比較能夠平行化,功能做得太靈活可能就會變成得要serialize,那就會減弱平行能力了。
> 任務級的OOO與指令級OOO是有區別的。 你理解有錯位的地方. 一個是軟件層OOO, 一個是硬件指令級OOO. 循序CORE完全可以來實現軟件層的OOO.
task level OOOE?你是不是指的是GPU的inter-warp OOOE?
那是現在這種時代的GPU理所當然應該得做到的啊。不然競爭力不夠的。
不然可能要再深入解釋一下。
warp內的OOOE的話似乎意義不大,不過先前RacingPHT兄在PIL提過另外一種別的說法,我不知道你指的是不是這種OOOE。:
http://we.pcinlife.com/…romuid=12048#pid17960419
>請教一下,以下是否是larrabee一些弱點呢?
>larrabee的tmu離shader太遠了. 有幾百個cycles的延遲.
>而GTX280的tmu到shader的延遲應該是小得多. 延遲上有大優勢.
可是這樣的話,GT200也因為shader和TMU直接固接連結,所以每個shader其實都只能用”那個TMU”….XD
這點RV770也一樣。
>還有頻寬問題, larrabee的內存控制器MC與L2與tmu都掛在ring bus上. 有點搞笑的是tmu向L2送sample都還要占用ring bus, 相當于耗費全局頻寬.
>太擁擠了.
老實說其實一樣啦。以G8x/G9x/GT200,還有RV770,從ROP的texture L2 cache到TMU的texture L1 cache中間的傳輸都是耗用所謂的”全局頻寬”,就是TPC/ROP等單位大家一起共用的一組internal bus(已知應該是crossbar)。
上面說的”TMU和shader固接連結”,就是靠bus來改善存取L2 texture cache,來讓它可以有效率地存取很多個不同位置的texture,所以L1 for sample(filtering),L2 for memory latency,空間和用途都是不太一樣的。
目前這一代DX10 GPU(RV770)都是讓shader unit以整個bank為單位,用time multiplx來share一個TMU,也就是一個bank擺一個(可能是G8x/RV770那樣4個一組、或者是G84~G9x/GT200以後的8 個一組),然後大家一起瓜分,這時候就有所謂的專用bus,filter過的東西也可以很快地傳給shader unit。然後要讀取的東西在定址後則經由texture cache L1/L2/memory controller分層從外面讀回來,這邊延遲很長但是沒關係,shader unit本身具備multi thread能力所以經得起等。
而Larrabee的話雖然說是ring bus,看起來效率比較低,不過它也是有固定比例(16core分 512bit),所以每個core相當於還是有一定程度的固定頻寬可用,那其實就沒差了;256KB L2 cache要看他們自己如何有效率地分配,而且這個機制也沒有驗證過,不知道能不能用。
總之bus的效率比較差,可以省下一些cost;但是同時增加的延遲就得準備更多的thread去吸收,結果就看哪邊成本比較高,來省哪邊….Intel顯然是cache做得太有自信了,所以大概覺得cache都可以搞定;當然真的搞定了還是得拍拍手就是。_A_
精確地說是sample的reuse問題. 與原始texture的reuse問題有區別. tmu的texture cache是用來reuse原始texture的.
第一個問題是sample是否可能reuse? sample是否存在有效的區域性?
你們認為按GPU或larrabee的工作模式,并沒有什么區域性. 或者很難發現區域性,例如U,V坐標是否相同?
尤其是對于GPU而言,
“waffenss:一般GPU的TMU和Shader core很密切,TMU可以把資料放到Shader core可以直接動用的register file”,以及”即使不同core去存取L2的filtering texcolor.
它也無法判斷是否是同一個位置.
因為不知道材質UV座標是否相同….
所以沒有共用性可言.”
“沒有任何局部性/區域性,也沒有reuse的概念.
因為你不會存取同一個位置.
就算是存取相鄰近位置,TMU也是要重新做filtering.
每次的color值都是獨一無二的.”
“Eji:而是 texture sample,或者是一個color,所以當然是每個pixel需要都得重算,沒有re-use的機會..”
是否存在有效的區域性呢? 對于GPU應該是很難存在. 對于larrabee也是一樣的.
第二個問題是如果存在,如何利用它? 對于GPU應該是沒有可能.
舉個特別的例子,如果是渲染200個簡單而且大小相同的純2D平面, 它們都要用到相同的一塊32X32 texture的情況下.
larrabee有個特殊性,那就是sample結果是由tmu存儲到L2里面的, 所以larrabee采取合適的編程,在有的場景下,例如:可能是透過L2命令tmu把一塊texture(大小位32X32像素)的所有sample送到L2里面來, 而非如同GPU要求sample放到寄存器里面來. GPU的寄存器是有限的, 沒有可能裝下, GPU寄存器是接收到一個sample/color, 而larrabee是一片sample/color.
關于U,V定位的問題, larrabee采取合適的編程或指令,或許可以有特定的尋址功能, U,V相同時, 地址也會相同, 可以準確定位. 用尋址映射來處理. 多個fiber或線程可以共享reuse它了.
所以pixel并非需要都得tmu重算200遍,而是就計算一遍.
對于其他的某些例子
或許larrabee還可以使用更低開銷的方式, 透過L2命令tmu把一塊texture(32X32)的某一個sample送到L2里面來, 根據其U,V映射到特定的地址里去存儲. (可以看成L2命令tmu把一塊texture(32X32)的所有sample送到L2里面來, 但是tmu可以偷懶就送來了一個sample,而存放方式卻是按照U,V映射的地址就可以啦)
而原始texture即使U,V相同,可能過濾后還是會產生無數種獨一無二的新texture? 這個問題有沒有呢? 還是請教一下兩位.
如果有的話, 或許還要給新texture塊新的編號ID才行.
由于架構差異,很多GPU的shader不可能知道的信息, larrabee卻可能知道. 很多對于shader透明的東西,larrabee可能知道. larrabee有可能在一定條件下,克服reuse時的U,V定位問題.
>畢竟要學類似N/A那種multi-bank register file大概都會扯到既有專利,所以intel他們是為了把手上的資源做最大效用發揮所以選擇這個途徑。
GMA是主要用reg吧? 應該是已經偷偷侵犯既有專利了.
>但是即使如此,我還是沒看過software renderer在衝OOOE的…. 畢竟一個frame還是要全部完成了才能送出來。
OOO的含義僅僅是亂序, 可以說硬件的,也可以軟件的, 可以是指令級的也可能是任務級的. 你可能是特指某類形式吧? 一談到OOO,你就想起了core2處理器?
如果將來有api配合的話, larrabee應該有某類software rander是幀級別的OOO的, 有時可能會前一幀frame還沒有全部完成,第二幀的ROP已經開始計算了,第三幀的PS已經開始計算了,第四幀的VS已經開始,第五幀都算好了. 只不過是結果送出來的時候,還是12345的循序in order而已. (雖然無關了,你觀察core2的OOO,core2也是OOO執行,送出來的時候按照循序提交.)
而一般情況下,larrabee software rander像素渲染任務級別的OOO的,就更常見了. 其實,GTX280也是OOO啊,就是larrabee說software rander的OOO的機會要更多一點而已.
可能是OOO的含義,你一開始有點想到指令級OOO上去了? 可以看看原文里面談到OOO,應該就是說發現或創造機會讓更多的任務可以平行執行. 問題就是出在你對OOO的理解含義上啦. 看原文好了.
>總之bus的效率比較差,可以省下一些cost;但是同時增加的延遲就得準備更多的thread去吸收,結果就看哪邊成本比較高,來省哪邊….
>Intel顯然是cache做得太有自信了,所以大概覺得cache都可以搞定;當然真的搞定了還是得拍拍手就是。_A_
larrabee的thread太少了, 延遲吸收很低效. cache可能對computer shader有幫助,而對已經上市的游戲,cache有多大用? cache如何與reg相比呢? 相差太遠了.
精確地說是sample的reuse問題. 與原始texture的reuse問題有區別. tmu的texture cache是用來reuse原始texture的.
第一個問題是sample是否可能reuse? sample是否存在有效的區域性?
你們認為按GPU或larrabee的工作模式,并沒有什么區域性. 或者很難發現區域性,例如U,V坐標是否相同?
尤其是對于GPU而言,
“waffenss:一般GPU的TMU和Shader core很密切,TMU可以把資料放到Shader core可以直接動用的register file”,以及”即使不同core去存取L2的filtering texcolor.
它也無法判斷是否是同一個位置.
因為不知道材質UV座標是否相同….
所以沒有共用性可言.”
“沒有任何局部性/區域性,也沒有reuse的概念.
因為你不會存取同一個位置.
就算是存取相鄰近位置,TMU也是要重新做filtering.
每次的color值都是獨一無二的.”
“Eji:而是 texture sample,或者是一個color,所以當然是每個pixel需要都得重算,沒有re-use的機會..”
是否存在有效的區域性呢? 對于GPU應該是很難存在. 對于larrabee也是一樣的.
第二個問題是如果存在,如何利用它? 對于GPU應該是沒有可能.
舉個特別的例子,如果是渲染200個簡單而且大小相同的純2D平面, 它們都要用到相同的一塊32X32 texture的情況下.
larrabee有個特殊性,那就是sample結果是由tmu存儲到L2里面的, 所以larrabee采取合適的編程,在有的場景下,例如:可能是透過L2命令tmu把一塊texture(大小位32X32像素)的所有sample送到L2里面來, 而非如同GPU要求sample放到寄存器里面來. GPU的寄存器是有限的, 沒有可能裝下, GPU寄存器是接收到一個sample/color, 而larrabee是一片sample/color.
關于U,V定位的問題, larrabee采取合適的編程或指令,或許可以有特定的尋址功能, U,V相同時, 地址也會相同, 可以準確定位. 用尋址映射來處理. 多個fiber或線程可以共享reuse它了.
所以pixel并非需要都得tmu重算200遍,而是就計算一遍.
對于其他的某些例子
或許larrabee還可以使用更低開銷的方式, 透過L2命令tmu把一塊texture(32X32)的某一個sample送到L2里面來, 根據其U,V映射到特定的地址里去存儲. (可以看成L2命令tmu把一塊texture(32X32)的所有sample送到L2里面來, 但是tmu可以偷懶就送來了一個sample,而存放方式卻是按照U,V映射的地址就可以啦)
而原始texture即使U,V相同,可能過濾后還是會產生無數種獨一無二的新texture? 這個問題有沒有呢? 還是請教一下兩位.
如果有的話, 或許還要給新texture塊新的編號ID才行.
由于架構差異,很多GPU的shader不可能知道的信息, larrabee卻可能知道. 很多對于shader透明的東西,larrabee可能知道. larrabee有可能在一定條件下,克服reuse時的U,V定位問題.
>畢竟要學類似N/A那種multi-bank register file大概都會扯到既有專利,所以intel他們是為了把手上的資源做最大效用發揮所以選擇這個途徑。
GMA是主要用reg吧? 應該是已經偷偷侵犯既有專利了.
>但是即使如此,我還是沒看過software renderer在衝OOOE的…. 畢竟一個frame還是要全部完成了才能送出來。
OOO的含義僅僅是亂序, 可以說硬件的,也可以軟件的, 可以是指令級的也可能是任務級的. 你可能是特指某類形式吧? 一談到OOO,你就想起了core2處理器?
如果將來有api配合的話, larrabee應該有某類software rander是幀級別的OOO的, 有時可能會前一幀frame還沒有全部完成,第二幀的ROP已經開始計算了,第三幀的PS已經開始計算了,第四幀的VS已經開始,第五幀都算好了. 只不過是結果送出來的時候,還是12345的循序in order而已. (雖然無關了,你觀察core2的OOO,core2也是OOO執行,送出來的時候按照循序提交.)
而一般情況下,larrabee software rander像素渲染任務級別的OOO的,就更常見了. 其實,GTX280也是OOO啊,就是larrabee說software rander的OOO的機會要更多一點而已.
可能是OOO的含義,你一開始有點想到指令級OOO上去了? 可以看看原文里面談到OOO,應該就是說發現或創造機會讓更多的任務可以平行執行. 問題就是出在你對OOO的理解含義上啦. 看原文好了.
>總之bus的效率比較差,可以省下一些cost;但是同時增加的延遲就得準備更多的thread去吸收,結果就看哪邊成本比較高,來省哪邊….
>Intel顯然是cache做得太有自信了,所以大概覺得cache都可以搞定;當然真的搞定了還是得拍拍手就是。_A_
larrabee的thread太少了, 延遲吸收很低效. cache可能對computer shader有幫助,而對已經上市的游戲,cache有多大用? cache如何與reg相比呢? 相差太遠了.
>>舉個特別的例子,如果是渲染200個簡單而且大小
>>相同的純2D平面, 它們都要用到相同的一塊32X32 >>texture的情況下.
如果你是跑”遊戲的pixel shader”.
遊戲的shader是把材質的編號和該點的UV座標傳給TMU.
然後取回filtering texcolor.
shader沒辦法不透過TMU取得texcolor.
shader是無法對記憶體某一位置去定址存取的.
正在跑shader的larrabee當然也不可能做到…
因為shader code根本沒有提供這樣的訊息給cpu.
除非你根本不跑遊戲shader,而是跑自己特製的2d程式碼.
這做法已經不是3D繪圖了.
這樣做出來的東西,會是純軟體2D繪圖.
而且不相容於其他GPU硬體,當然也沒有shader.
可能比較偏GPGPU的領域,
不過應該沒有人會用GPGPU來跑2D軟體繪圖,
沒必要把簡單事情稿的這麼複雜吧…..
直接用硬體加速把200個2d平面畫出來就好了.
其實遊戲裡的共用數字圖,例如分數0~9
就是直接畫出來. 雖然0可能出現10次.
那tmu就做10次point sampling嘛.
其實那根本不耗效能…..
對一般GPU來說TMU是免費的硬體,你不用也沒好處阿.
>>舉個特別的例子,如果是渲染200個簡單而且大小
>>相同的純2D平面, 它們都要用到相同的一塊32X32 >>texture的情況下.
如果你是跑”遊戲的pixel shader”.
遊戲的shader是把材質的編號和該點的UV座標傳給TMU.
然後取回filtering texcolor.
shader沒辦法不透過TMU取得texcolor.
shader是無法對記憶體某一位置去定址存取的.
正在跑shader的larrabee當然也不可能做到…
因為shader code根本沒有提供這樣的訊息給cpu.
除非你根本不跑遊戲shader,而是跑自己特製的2d程式碼.
這做法已經不是3D繪圖了.
這樣做出來的東西,會是純軟體2D繪圖.
而且不相容於其他GPU硬體,當然也沒有shader.
可能比較偏GPGPU的領域,
不過應該沒有人會用GPGPU來跑2D軟體繪圖,
沒必要把簡單事情稿的這麼複雜吧…..
直接用硬體加速把200個2d平面畫出來就好了.
其實遊戲裡的共用數字圖,例如分數0~9
就是直接畫出來. 雖然0可能出現10次.
那tmu就做10次point sampling嘛.
其實那根本不耗效能…..
對一般GPU來說TMU是免費的硬體,你不用也沒好處阿.
>精確地說是sample的reuse問題. 與原始texture的reuse問題有區別. tmu的texture cache是用來reuse原始texture的.
>第一個問題是sample是否可能reuse? sample是否存在有效的區域性?
>你們認為按GPU或larrabee的工作模式,并沒有什么區域性. 或者很難發現區域性,例如U,V坐標是否相同?
>尤其是對于GPU而言,
sample的reuse比較困難啦….XD
首先UV座標就不可能一樣,因為你同一個點只會畫一次XD
(當座標不同,像素首先就不會是一樣的東西)
因為在繪圖上,隨著shader複雜化,會跟著使用越來越大的texture,而對繪圖而言,預期texture的內容有重複是不適當的。XD
這點我們可以從id的MegaTexture技術看得出來,即使製作過程其實很多小texture透過metadata重組的方式產生很大的材質,但是那其實是試圖讓artist可以很快地做出銜接自然的材質;而最終目的是產生材質上的每一個部分都是獨一無二的。
所以說你假設的這個資料重複使用性,我想並不屬於繪圖工作的特性,而比較像是某些HPC範疇。
>是否存在有效的區域性呢? 對于GPU應該是很難存在. 對于larrabee也是一樣的.
>第二個問題是如果存在,如何利用它? 對于GPU應該是沒有可能.
GPU能夠快速的理由,是因為無依存性的高度平行化,在此同時可以re-use的資料相當稀少,即使是vertex shader和geometry shader之類可能有部分re-use資料的狀況,其實也都是類似某種data de-compression的觀念,是從一個小資料透過演算法放大出來,從極端地說它每一小塊資料也只使用一次而已,因為放大後就flush掉做下一塊了。
>舉個特別的例子,如果是渲染200個簡單而且大小相同的純2D平面, 它們都要用到相同的一塊32X32 texture的情況下.
>larrabee有個特殊性,那就是sample結果是由tmu存儲到L2里面的, 所以larrabee采取合適的編程,在有的場景下,例如:可能是透過L2命令tmu把一塊texture(大小位32X32像素)的所有sample送到L2里面來, 而非如同GPU要求sample放到寄存器里面來. GPU的寄存器是有限的, 沒有可能裝下, GPU寄存器是接收到一個sample/color, 而larrabee是一片sample/color.
>關于U,V定位的問題, larrabee采取合適的編程或指令,或許可以有特定的尋址功能, U,V相同時, 地址也會相同, 可以準確定位. 用尋址映射來處理. 多個fiber或線程可以共享reuse它了.
>所以pixel并非需要都得tmu重算200遍,而是就計算一遍.
我覺得這個思考有個問題:
1. sample其實是shader送出”需要的座標”給TMU之後,作filter再送過來,所以每個sample都是不同的,照你所說Larrabee取入”一片sample”的時候,其實只是把這些sample對cache以分片的方式載入;而其實在這個定義下,GPU也是取入大量的sample。
2. 你覺得GPU的register有限,但是register在這時候其實是以蜂巢狀的結構來取入需要的材質,而GPU的register file由於極為巨大,其實速度並沒有你想像中的快,比方說G8x存取share memory和register file的速度其實是一樣的,都是4cycle latency。
>對于其他的某些例子
>或許larrabee還可以使用更低開銷的方式, 透過L2命令tmu把一塊texture(32X32)的某一個sample送到L2里面來, 根據其U,V映射到特定的地址里去存儲. (可以看成L2命令tmu把一塊texture(32X32)的所有sample送到L2里面來, 但是tmu可以偷懶就送來了一個sample,而存放方式卻是按照U,V映射的地址就可以啦)
>而原始texture即使U,V相同,可能過濾后還是會產生無數種獨一無二的新texture? 這個問題有沒有呢? 還是請教一下兩位.
>如果有的話, 或許還要給新texture塊新的編號ID才行.
wait,UV座標指的是曲面上的一個交點位置,所以代表的是”模型上的位置”,為什麼你要考量UV座標一樣的東西?過去我們在這種狀況指的是multi-texturing所以會疊合數份完全不同的材質來創造出較複雜的色彩,才會需要所謂的UV座標相同的狀況;但是這又和你的材質相同假設有衝突喔?
也就是說,如果材質小的話就變成要散佈到很多座標不同的地方,那麼filtered後產生sample內容就一定不同;但是如果UV座標相同的話,通常也代表的是很多texture再經過filter後得來的sample再疊合,結果還是內容會不同。
>由于架構差異,很多GPU的shader不可能知道的信息, larrabee卻可能知道. 很多對于shader透明的東西,larrabee可能知道. larrabee有可能在一定條件下,克服reuse時的U,V定位問題.
可是我覺得shader不知道的信息,演算法核心還是會知道….
如果考慮那麼不容易平行化的資料re-use機制,其實這個演算法本身在繪圖上很可能已經不容易高速了。
>GMA是主要用reg吧? 應該是已經偷偷侵犯既有專利了.
GMA用register倒本身不是侵犯專利,NVIDIA和ATI的專利主要在排程上,但是GMA的triangle setup 是由shader來執行,沒有用hardwire unit,這就算是另一種迴避專利,性能也跟著就拉不起來。
GMA的shader unit (execution unit, EU)的編號是4bit的,最大是16組1D、而實際上GMA目前在G45也只做到10EUs。
>OOO的含義僅僅是亂序, 可以說硬件的,也可以軟件的, 可以是指令級的也可能是任務級的. 你可能是特指某類形式吧? 一談到OOO,你就想起了core2處理器?
>如果將來有api配合的話, larrabee應該有某類software rander是幀級別的OOO的, 有時可能會前一幀frame還沒有全部完成,第二幀的ROP已經開始計算了,第三幀的PS已經開始計算了,第四幀的VS已經開始,第五幀都算好了. 只不過是結果送出來的時候,還是12345的循序in order而已. (雖然無關了,你觀察core2的OOO,core2也是OOO執行,送出來的時候按照循序提交.)
這邊有個疑問是,為什麼某些frame會比較快或比較慢?早執行完這些frame會比較有意義嗎?目的應該是快速地執行當下的frame才是啊?
以目前的OOOE,應該是執行frame裡面快or慢的部分….或者是說為什麼要預期先算後面的frame會比較好….?
>而一般情況下,larrabee software rander像素渲染任務級別的OOO的,就更常見了. 其實,GTX280也是OOO啊,就是larrabee說software rander的OOO的機會要更多一點而已.
一般的GPU都是frame內的OOO,我不知道frame間的OOO有什麼幫助喔….因為每個frame內容都還會受到user的行為影響啊,畢竟你又無法完全預期user的行為,難道你是在說offline rendering?
>larrabee的thread太少了, 延遲吸收很低效. cache可能對computer shader有幫助,而對已經上市的游戲,cache有多大用? cache如何與reg相比呢? 相差太遠了.
我不覺得如此耶,GPU的register並不是CPU那種速度喔。
其實論從cache裡面做類似scratchpad那樣的分段交換,和GPU用硬體把這段sehedule做成硬體或者部分可控制來說,行為是類似的,重點是”真正快的register一定只有一小段”,設計上當然不可能說高達64KB的register file,每一個register都和實際的128 register一樣快,routing再怎麼神都做不到的;x86的指令集又很依賴memory access,所以cache效率常常做到匪夷所思的地步,事實上NetBurst裡面cache就有些case是和register差不多快的。
所以真的要我說賭GPU vendor做的register file和Intel的cache子系統到底哪個比較快,我覺得真的是蠻難說的,當然intel是已經賭他們贏了啦….
此外,ring bus本身其實也是可以吸收一些latency,由於他們宣稱512bit for 16core是定規,如果要強化的話就是加memory access port或者是TMU到ring bus上,還有even/odd clock雙向傳輸,可以預期的是基本上512bit x 1GHz x 16= 8Gbps的單向傳輸頻寬是沒有問題的,以目前來說其實Larrabee在帳面上的硬體spec是沒問題的,現在的問題反倒是他們是不是真的能做出那個帳面上的硬體,還有沒在帳面上的軟體排程能力(依存於compiler)是不是真的可以符合需求。
>精確地說是sample的reuse問題. 與原始texture的reuse問題有區別. tmu的texture cache是用來reuse原始texture的.
>第一個問題是sample是否可能reuse? sample是否存在有效的區域性?
>你們認為按GPU或larrabee的工作模式,并沒有什么區域性. 或者很難發現區域性,例如U,V坐標是否相同?
>尤其是對于GPU而言,
sample的reuse比較困難啦….XD
首先UV座標就不可能一樣,因為你同一個點只會畫一次XD
(當座標不同,像素首先就不會是一樣的東西)
因為在繪圖上,隨著shader複雜化,會跟著使用越來越大的texture,而對繪圖而言,預期texture的內容有重複是不適當的。XD
這點我們可以從id的MegaTexture技術看得出來,即使製作過程其實很多小texture透過metadata重組的方式產生很大的材質,但是那其實是試圖讓artist可以很快地做出銜接自然的材質;而最終目的是產生材質上的每一個部分都是獨一無二的。
所以說你假設的這個資料重複使用性,我想並不屬於繪圖工作的特性,而比較像是某些HPC範疇。
>是否存在有效的區域性呢? 對于GPU應該是很難存在. 對于larrabee也是一樣的.
>第二個問題是如果存在,如何利用它? 對于GPU應該是沒有可能.
GPU能夠快速的理由,是因為無依存性的高度平行化,在此同時可以re-use的資料相當稀少,即使是vertex shader和geometry shader之類可能有部分re-use資料的狀況,其實也都是類似某種data de-compression的觀念,是從一個小資料透過演算法放大出來,從極端地說它每一小塊資料也只使用一次而已,因為放大後就flush掉做下一塊了。
>舉個特別的例子,如果是渲染200個簡單而且大小相同的純2D平面, 它們都要用到相同的一塊32X32 texture的情況下.
>larrabee有個特殊性,那就是sample結果是由tmu存儲到L2里面的, 所以larrabee采取合適的編程,在有的場景下,例如:可能是透過L2命令tmu把一塊texture(大小位32X32像素)的所有sample送到L2里面來, 而非如同GPU要求sample放到寄存器里面來. GPU的寄存器是有限的, 沒有可能裝下, GPU寄存器是接收到一個sample/color, 而larrabee是一片sample/color.
>關于U,V定位的問題, larrabee采取合適的編程或指令,或許可以有特定的尋址功能, U,V相同時, 地址也會相同, 可以準確定位. 用尋址映射來處理. 多個fiber或線程可以共享reuse它了.
>所以pixel并非需要都得tmu重算200遍,而是就計算一遍.
我覺得這個思考有個問題:
1. sample其實是shader送出”需要的座標”給TMU之後,作filter再送過來,所以每個sample都是不同的,照你所說Larrabee取入”一片sample”的時候,其實只是把這些sample對cache以分片的方式載入;而其實在這個定義下,GPU也是取入大量的sample。
2. 你覺得GPU的register有限,但是register在這時候其實是以蜂巢狀的結構來取入需要的材質,而GPU的register file由於極為巨大,其實速度並沒有你想像中的快,比方說G8x存取share memory和register file的速度其實是一樣的,都是4cycle latency。
>對于其他的某些例子
>或許larrabee還可以使用更低開銷的方式, 透過L2命令tmu把一塊texture(32X32)的某一個sample送到L2里面來, 根據其U,V映射到特定的地址里去存儲. (可以看成L2命令tmu把一塊texture(32X32)的所有sample送到L2里面來, 但是tmu可以偷懶就送來了一個sample,而存放方式卻是按照U,V映射的地址就可以啦)
>而原始texture即使U,V相同,可能過濾后還是會產生無數種獨一無二的新texture? 這個問題有沒有呢? 還是請教一下兩位.
>如果有的話, 或許還要給新texture塊新的編號ID才行.
wait,UV座標指的是曲面上的一個交點位置,所以代表的是”模型上的位置”,為什麼你要考量UV座標一樣的東西?過去我們在這種狀況指的是multi-texturing所以會疊合數份完全不同的材質來創造出較複雜的色彩,才會需要所謂的UV座標相同的狀況;但是這又和你的材質相同假設有衝突喔?
也就是說,如果材質小的話就變成要散佈到很多座標不同的地方,那麼filtered後產生sample內容就一定不同;但是如果UV座標相同的話,通常也代表的是很多texture再經過filter後得來的sample再疊合,結果還是內容會不同。
>由于架構差異,很多GPU的shader不可能知道的信息, larrabee卻可能知道. 很多對于shader透明的東西,larrabee可能知道. larrabee有可能在一定條件下,克服reuse時的U,V定位問題.
可是我覺得shader不知道的信息,演算法核心還是會知道….
如果考慮那麼不容易平行化的資料re-use機制,其實這個演算法本身在繪圖上很可能已經不容易高速了。
>GMA是主要用reg吧? 應該是已經偷偷侵犯既有專利了.
GMA用register倒本身不是侵犯專利,NVIDIA和ATI的專利主要在排程上,但是GMA的triangle setup 是由shader來執行,沒有用hardwire unit,這就算是另一種迴避專利,性能也跟著就拉不起來。
GMA的shader unit (execution unit, EU)的編號是4bit的,最大是16組1D、而實際上GMA目前在G45也只做到10EUs。
>OOO的含義僅僅是亂序, 可以說硬件的,也可以軟件的, 可以是指令級的也可能是任務級的. 你可能是特指某類形式吧? 一談到OOO,你就想起了core2處理器?
>如果將來有api配合的話, larrabee應該有某類software rander是幀級別的OOO的, 有時可能會前一幀frame還沒有全部完成,第二幀的ROP已經開始計算了,第三幀的PS已經開始計算了,第四幀的VS已經開始,第五幀都算好了. 只不過是結果送出來的時候,還是12345的循序in order而已. (雖然無關了,你觀察core2的OOO,core2也是OOO執行,送出來的時候按照循序提交.)
這邊有個疑問是,為什麼某些frame會比較快或比較慢?早執行完這些frame會比較有意義嗎?目的應該是快速地執行當下的frame才是啊?
以目前的OOOE,應該是執行frame裡面快or慢的部分….或者是說為什麼要預期先算後面的frame會比較好….?
>而一般情況下,larrabee software rander像素渲染任務級別的OOO的,就更常見了. 其實,GTX280也是OOO啊,就是larrabee說software rander的OOO的機會要更多一點而已.
一般的GPU都是frame內的OOO,我不知道frame間的OOO有什麼幫助喔….因為每個frame內容都還會受到user的行為影響啊,畢竟你又無法完全預期user的行為,難道你是在說offline rendering?
>larrabee的thread太少了, 延遲吸收很低效. cache可能對computer shader有幫助,而對已經上市的游戲,cache有多大用? cache如何與reg相比呢? 相差太遠了.
我不覺得如此耶,GPU的register並不是CPU那種速度喔。
其實論從cache裡面做類似scratchpad那樣的分段交換,和GPU用硬體把這段sehedule做成硬體或者部分可控制來說,行為是類似的,重點是”真正快的register一定只有一小段”,設計上當然不可能說高達64KB的register file,每一個register都和實際的128 register一樣快,routing再怎麼神都做不到的;x86的指令集又很依賴memory access,所以cache效率常常做到匪夷所思的地步,事實上NetBurst裡面cache就有些case是和register差不多快的。
所以真的要我說賭GPU vendor做的register file和Intel的cache子系統到底哪個比較快,我覺得真的是蠻難說的,當然intel是已經賭他們贏了啦….
此外,ring bus本身其實也是可以吸收一些latency,由於他們宣稱512bit for 16core是定規,如果要強化的話就是加memory access port或者是TMU到ring bus上,還有even/odd clock雙向傳輸,可以預期的是基本上512bit x 1GHz x 16= 8Gbps的單向傳輸頻寬是沒有問題的,以目前來說其實Larrabee在帳面上的硬體spec是沒問題的,現在的問題反倒是他們是不是真的能做出那個帳面上的硬體,還有沒在帳面上的軟體排程能力(依存於compiler)是不是真的可以符合需求。
>waffenss:如果你是跑”遊戲的pixel shader”.
>遊戲的shader是把材質的編號和該點的UV座標傳給TMU.
>然後取回filtering texcolor.
>shader沒辦法不透過TMU取得texcolor.
>shader是無法對記憶體某一位置去定址存取的.
>正在跑shader的larrabee當然也不可能做到…
>因為shader code根本沒有提供這樣的訊息給cpu.
shader的源program是不知道, 但是larrabee知道如何編譯能讓shader的機器碼他能知道.
>Eji:sample的reuse比較困難啦….XD
>首先UV座標就不可能一樣,因為你同一個點只會畫一次XD
一般而言, 一個fiber/thread是同一個點只會畫一次, 但是其他fiber或thread呢? 有可能會用到同一塊texture,相同U,V位置的sample.
要從更大的尺度看,例如,非僅僅一個shader,而是多個shader.
前面舉例,多個平面,需要使用到相同的texture. 它們都要重復200次用到同一塊texture,都要重復200次用到相同U,V位置的sample.
清楚你的意思了, 但是此類型的區域性, 對于游戲, 你認為并沒有實際利用價值是吧?
所以問題是: 此類的區域性是否有實際利用價值? 如果有,如何利用呢? larrabee會很困難吧?
對于larrabee而言,問題是變為經過過濾的texture,是否有區域性可以利用?
對于GPU而言, 問題是變為sample是否有區域性可以利用? 顯然沒有.
>GPU能夠快速的理由,是因為無依存性的高度平行化,在此同時可以re-use的資料相當稀少,即使是vertex shader和geometry shader之類可能有部分re-use資料的狀況,其實也都是類似某種data de-compression的觀念,是從一個小資料透過演算法放大出來,從極端地說它每一小塊資料也只使用一次而已,因為放大後就flush掉做下一塊了。
看來texture cache也幾乎很少利用上texture的區域性? texture cache是為了什么呢? 或許是為了存放texture constant?
>1. sample其實是shader送出”需要的座標”給TMU之後,作filter再送過來,所以每個sample都是不同的,照你所說Larrabee取入”一片sample”的時候,其實只是把這些sample對cache以分片的方式載入;而其實在這個定義下,GPU也是取入大量的sample。
關鍵是送到以后, 說的極端點,是把全部(上千個)sample都能存儲到L2里面, 全部的sample結果可以同時存在. 而GPU是如何呢? shader的寄存器是有限的, 能同時存儲? 可能是FIFO里面還能有幾個sample吧?
>2. 你覺得GPU的register有限,但是register在這時候其實是以蜂巢狀的結構來取入需要的材質,而GPU的register file由於極為巨大,其實速度並沒有你想像中的快,比方說G8x存取share memory和register file的速度其實是一樣的,都是4cycle latency
與L2相比, GPU的register file是沒有多少空間來裝sample的,極為巨大的是L2.
或者你可以看成larrabee神奇的擁有極為巨大數量的多個跨線程跨fiber的全局寄存器reg, laraabee透過合適的編程,設法讓多個線程/fiber能reuse那些寄存器里面的sample. 那些寄存器都有唯一的代號–對應U,V坐標與texture的編號. 例如U=2,V=6,texture編號0x777795, sample就對應0xffffff7777950206號寄存器. 多個線程/fiber都能reuse它. 指令如何reuse它? 可能是某類專用指令 fetchsample [rax], 而rax=0xffffff7777950206.
當然啦, 寄存器代號如何編碼,還是很靈活的,僅僅是舉例.
而相對說來,GPU的寄存器都是私有的,thread A無法訪問thread B的寄存器,所以難以reuse.
>wait,UV座標指的是曲面上的一個交點位置,所以代表的是”模型上的位置”,為什麼你要考量UV座標一樣的東西?過去我們在這種狀況指的是multi-texturing所以會疊合數份完全不同的材質來創造出較複雜的色彩,才會需要所謂的UV座標相同的狀況;但是這又和你的材質相同假設有衝突喔?
假設同一個texture上U,V相同,但sample結果卻不同的情況,那就相當復雜了. 就是問你啊? 對于同一個texture而言, 如果U,V相同,是否sample的結果會有區別. 要是有區別就給它一個新的ID.
>這邊有個疑問是,為什麼某些frame會比較快或比較慢?早執行完這些frame會比較有意義嗎?目的應該是快速地執行當下的frame才是啊?
以目前的OOOE,應該是執行frame裡面快or慢的部分….或者是說為什麼要預期先算後面的frame會比較好….?
為了讓VPU跑滿載所有核心都跑滿, 例如,5幀一共耗時50ms, 還是比5幀一共耗時70ms要快上一大截. 為了減少總耗時. 說的極端點,vpu可能由于load平衡等問題,第一幀有一個很慢的,而又無法平行化的任務,它僅僅使用了一個核心來計算也要要等很久才能算好, 如果有機會,后面的幀frame就要設法OOO,讓其他核心都運算起來.
>一般的GPU都是frame內的OOO,我不知道frame間的OOO有什麼幫助喔….因為每個frame內容都還會受到user的行為影響啊,畢竟你又無法完全預期user的行為,難道你是在說offline rendering?
是舉例罷了,將來api的的配合下,實現高級別的OOO,提高整體效率.
>其實論從cache裡面做類似scratchpad那樣的分段交換,和GPU用硬體把這段sehedule做成硬體或者部分可控制來說,行為是類似的,重點是”真正快的register一定只有一小段”,設計上當然不可能說高達64KB的register file,每一個register都和實際的128 register一樣快,routing再怎麼神都做不到的;x86的指令集又很依賴memory access,所以cache效率常常做到匪夷所思的地步,事實上NetBurst裡面cache就有些case是和register差不多快的。
延遲比較原來是如此啊. reg可以直接參與計算,可以是dest或source, cache僅能提供一個源操作數source, larrabee的isa效率要低很多.
例如:
reg0=reg1-reg2
而cache就無法實現[memory0]=[memory1]-[memory2]了
需要多條消耗多條指令:
1.load regA=[memory1]
2.然后減法regB=regA-[memory2]
3.然后是store存[memory0]=regB
>在的問題反倒是他們是不是真的能做出那個帳面上的硬體,還有沒在帳面上的軟體排程能力(依存於compiler)是不是真的可以符合需求。
難道說是,硬件上已經性能過硬? 你擔心的是制造成本與難度, 以及軟體上問題. 除了那些問題, 應該還有頻寬的問題.
ring bus太擁擠了. 單向的情況下, 是512bit, 如果是半速的, 那就是16個核心分用32Byte*1G=64GB/cycle的頻寬.
memory與L2之間傳資料要占用ringbus–core訪問memory要占用ringbus, tmu向L2送sample要占用ring bus, L2之間的資料傳輸也要占用ring bus. 應該是很低效.
>waffenss:如果你是跑”遊戲的pixel shader”.
>遊戲的shader是把材質的編號和該點的UV座標傳給TMU.
>然後取回filtering texcolor.
>shader沒辦法不透過TMU取得texcolor.
>shader是無法對記憶體某一位置去定址存取的.
>正在跑shader的larrabee當然也不可能做到…
>因為shader code根本沒有提供這樣的訊息給cpu.
shader的源program是不知道, 但是larrabee知道如何編譯能讓shader的機器碼他能知道.
>Eji:sample的reuse比較困難啦….XD
>首先UV座標就不可能一樣,因為你同一個點只會畫一次XD
一般而言, 一個fiber/thread是同一個點只會畫一次, 但是其他fiber或thread呢? 有可能會用到同一塊texture,相同U,V位置的sample.
要從更大的尺度看,例如,非僅僅一個shader,而是多個shader.
前面舉例,多個平面,需要使用到相同的texture. 它們都要重復200次用到同一塊texture,都要重復200次用到相同U,V位置的sample.
清楚你的意思了, 但是此類型的區域性, 對于游戲, 你認為并沒有實際利用價值是吧?
所以問題是: 此類的區域性是否有實際利用價值? 如果有,如何利用呢? larrabee會很困難吧?
對于larrabee而言,問題是變為經過過濾的texture,是否有區域性可以利用?
對于GPU而言, 問題是變為sample是否有區域性可以利用? 顯然沒有.
>GPU能夠快速的理由,是因為無依存性的高度平行化,在此同時可以re-use的資料相當稀少,即使是vertex shader和geometry shader之類可能有部分re-use資料的狀況,其實也都是類似某種data de-compression的觀念,是從一個小資料透過演算法放大出來,從極端地說它每一小塊資料也只使用一次而已,因為放大後就flush掉做下一塊了。
看來texture cache也幾乎很少利用上texture的區域性? texture cache是為了什么呢? 或許是為了存放texture constant?
>1. sample其實是shader送出”需要的座標”給TMU之後,作filter再送過來,所以每個sample都是不同的,照你所說Larrabee取入”一片sample”的時候,其實只是把這些sample對cache以分片的方式載入;而其實在這個定義下,GPU也是取入大量的sample。
關鍵是送到以后, 說的極端點,是把全部(上千個)sample都能存儲到L2里面, 全部的sample結果可以同時存在. 而GPU是如何呢? shader的寄存器是有限的, 能同時存儲? 可能是FIFO里面還能有幾個sample吧?
>2. 你覺得GPU的register有限,但是register在這時候其實是以蜂巢狀的結構來取入需要的材質,而GPU的register file由於極為巨大,其實速度並沒有你想像中的快,比方說G8x存取share memory和register file的速度其實是一樣的,都是4cycle latency
與L2相比, GPU的register file是沒有多少空間來裝sample的,極為巨大的是L2.
或者你可以看成larrabee神奇的擁有極為巨大數量的多個跨線程跨fiber的全局寄存器reg, laraabee透過合適的編程,設法讓多個線程/fiber能reuse那些寄存器里面的sample. 那些寄存器都有唯一的代號–對應U,V坐標與texture的編號. 例如U=2,V=6,texture編號0x777795, sample就對應0xffffff7777950206號寄存器. 多個線程/fiber都能reuse它. 指令如何reuse它? 可能是某類專用指令 fetchsample [rax], 而rax=0xffffff7777950206.
當然啦, 寄存器代號如何編碼,還是很靈活的,僅僅是舉例.
而相對說來,GPU的寄存器都是私有的,thread A無法訪問thread B的寄存器,所以難以reuse.
>wait,UV座標指的是曲面上的一個交點位置,所以代表的是”模型上的位置”,為什麼你要考量UV座標一樣的東西?過去我們在這種狀況指的是multi-texturing所以會疊合數份完全不同的材質來創造出較複雜的色彩,才會需要所謂的UV座標相同的狀況;但是這又和你的材質相同假設有衝突喔?
假設同一個texture上U,V相同,但sample結果卻不同的情況,那就相當復雜了. 就是問你啊? 對于同一個texture而言, 如果U,V相同,是否sample的結果會有區別. 要是有區別就給它一個新的ID.
>這邊有個疑問是,為什麼某些frame會比較快或比較慢?早執行完這些frame會比較有意義嗎?目的應該是快速地執行當下的frame才是啊?
以目前的OOOE,應該是執行frame裡面快or慢的部分….或者是說為什麼要預期先算後面的frame會比較好….?
為了讓VPU跑滿載所有核心都跑滿, 例如,5幀一共耗時50ms, 還是比5幀一共耗時70ms要快上一大截. 為了減少總耗時. 說的極端點,vpu可能由于load平衡等問題,第一幀有一個很慢的,而又無法平行化的任務,它僅僅使用了一個核心來計算也要要等很久才能算好, 如果有機會,后面的幀frame就要設法OOO,讓其他核心都運算起來.
>一般的GPU都是frame內的OOO,我不知道frame間的OOO有什麼幫助喔….因為每個frame內容都還會受到user的行為影響啊,畢竟你又無法完全預期user的行為,難道你是在說offline rendering?
是舉例罷了,將來api的的配合下,實現高級別的OOO,提高整體效率.
>其實論從cache裡面做類似scratchpad那樣的分段交換,和GPU用硬體把這段sehedule做成硬體或者部分可控制來說,行為是類似的,重點是”真正快的register一定只有一小段”,設計上當然不可能說高達64KB的register file,每一個register都和實際的128 register一樣快,routing再怎麼神都做不到的;x86的指令集又很依賴memory access,所以cache效率常常做到匪夷所思的地步,事實上NetBurst裡面cache就有些case是和register差不多快的。
延遲比較原來是如此啊. reg可以直接參與計算,可以是dest或source, cache僅能提供一個源操作數source, larrabee的isa效率要低很多.
例如:
reg0=reg1-reg2
而cache就無法實現[memory0]=[memory1]-[memory2]了
需要多條消耗多條指令:
1.load regA=[memory1]
2.然后減法regB=regA-[memory2]
3.然后是store存[memory0]=regB
>在的問題反倒是他們是不是真的能做出那個帳面上的硬體,還有沒在帳面上的軟體排程能力(依存於compiler)是不是真的可以符合需求。
難道說是,硬件上已經性能過硬? 你擔心的是制造成本與難度, 以及軟體上問題. 除了那些問題, 應該還有頻寬的問題.
ring bus太擁擠了. 單向的情況下, 是512bit, 如果是半速的, 那就是16個核心分用32Byte*1G=64GB/cycle的頻寬.
memory與L2之間傳資料要占用ringbus–core訪問memory要占用ringbus, tmu向L2送sample要占用ring bus, L2之間的資料傳輸也要占用ring bus. 應該是很低效.
>>shader的源program是不知道,
>>但是larrabee知道如何編譯能讓
>>shader的機器碼他能知道.
等一下….
shader code是由driver”事先”compile成機器碼.
他不會知道200個2D物體UV座標是相同的.
然而它並不知道你那200個2D物體會不會有位移旋轉縮放.
物體在螢幕上的位置會導致sample的點不一樣.
畢竟物體的動態是engine即時提供的.
shader的編譯器只知道compile時的狀態.
在繪圖過程中,遊戲做任何變化是編譯器無法預期的.
compiler怎麼可能假定物體的screen space位置
一定不動呢? 這是不合理的預期.
而且編譯器也不知道你事後會不會動態更換貼圖….
不可能假定這模型只能跟這張貼圖吧.
(而且實際上,編譯器不會去檢查模型UV….
所以他根本不知道這200個物體貼的texel是否相同)
只有軟體2D繪圖有可能去知道這些資訊,
因為你的軟體算圖是自己寫在引擎內的,
愛怎麼做就怎麼做.
如果是跑一般3D遊戲的shader….就不可能這樣.
shader編譯其實是很單純的.
3D enine把shader code丟給API/Driver去處理時,
就只是單純把程式碼送過去而已,不會連模型貼圖都丟
給shader編譯器.
所以shader編譯器對於貼圖UV座標和頂點資訊….
是一蓋不知的.
編譯器也不會知道這些程式碼用哪一個模型哪一個貼圖.
那是遊戲進行時程式每frame送出繪圖要求時才指定的.
編譯器只知道程式碼會進行什麼計算,有幾組UV,
有用幾張貼圖…..
shader編譯其實是很單純的.
3D enine把shader code丟給API/Driver去處理時,
就只是單純把程式碼送過去而已,不會連模型貼圖都丟
給shader編譯器.
所以shader編譯器對於貼圖UV座標和頂點資訊….
是一蓋不知的.
編譯器也不會知道這些程式碼用哪一個模型哪一個貼圖.
那是遊戲進行時程式每frame送出繪圖要求時才指定的.
編譯器只知道程式碼會進行什麼計算,有幾組UV,
有用幾張貼圖…..
是larrabee(應該是負責管理shader的硬體或軟體)告訴shader那些資訊, 而shader是知道的應該到L2的哪里去讀取sample的.
例如
可能是某類專用指令 fetchsample [rax], 而 rax=0xffffff7777950206.
shader可以在不知道U,V的條件下,得到sample. rax的確定或遞增是由負責shader管理的硬體或軟體來進行的.
shader可以得到它,你也可以看成那是寄存器(其實是L2 cache). U,V座標是被映射到位址上的.
關於縮放–
texture相同,U,V也相同, sample就相同的假設,是否就難以成立了呢? 請教一下.
是larrabee(應該是負責管理shader的硬體或軟體)告訴shader那些資訊, 而shader是知道的應該到L2的哪里去讀取sample的.
例如
可能是某類專用指令 fetchsample [rax], 而 rax=0xffffff7777950206.
shader可以在不知道U,V的條件下,得到sample. rax的確定或遞增是由負責shader管理的硬體或軟體來進行的.
shader可以得到它,你也可以看成那是寄存器(其實是L2 cache). U,V座標是被映射到位址上的.
關於縮放–
texture相同,U,V也相同, sample就相同的假設,是否就難以成立了呢? 請教一下.
>一般而言, 一個fiber/thread是同一個點只會畫一次, 但是其他fiber或
>thread呢? 有可能會用到同一塊texture,相同U,V位置的sample.
>要從更大的尺度看,例如,非僅僅一個shader,而是多個shader.
重複繪製通常指的是overdraw,但是不是因為UV座標一樣而是因為同pixel,然後z-compare之後認定要reject掉。
上面說了,hardware pipeline不會去分辨相同UV座標的texel「是不是重複」,你說的這些都是software 3D engine面在資料結構上去減少各種不同性能虛耗的範疇,讓硬體設計面去思考這麼多問題,只會被越來越複雜的工作給拖慢。
事實上,thread間通訊是有必要的,但是都是在HPC用途底下,CUDA在這邊花了很多苦心,但是Larrabee這邊的優勢就像你說得很明顯,上面你所提的一些機制在Larrabee上因為是軟體排程,所以要做什麼相對的都很容易。
> 所以問題是: 此類的區域性是否有實際利用價值? 如果有,如何利用呢? larrabee會很困難吧?
> 對于larrabee而言,問題是變為經過過濾的texture,是否有區域性可以利用?
> 對于GPU而言, 問題是變為sample是否有區域性可以利用? 顯然沒有.
我現在不知道對繪圖而言reuse有什麼好處?
> 關鍵是送到以后, 說的極端點,是把全部(上千個)sample都能存儲到L2里> 面, 全部的sample結果可以同時存在. 而GPU是如何呢? shader的寄存> 器是有限的, 能同時存儲? 可能是FIFO里面還能有幾個sample吧?
GT200有64KB, G8x/G9x還是有32KB,R600系列也有256KB的register file,沒有小道哪去啊。
同時存儲?你也沒辦法把cache的所有內容同時取得、同時修改吧。
目前看來Larrabee也是靠cache控制指令,來使得部份的cache空間可以當成scratchpad memory來使用,比方說GT200的每個SM具有64KB的register file,最大則有32warp,所以代表的其實是可以以2KB為單位來作存取。如果在cache上要實現這種控制,只要實做cache line lock就可以了,每次lock個1~2KB(太小的話cache line,這樣就不會被同步機制給交換出去,反過來說就可以看成Larrabee有更多個warp。
但是這都是和thread interconnections沒有關係的,繪圖上是不會用到這些設計,所以這也是為什麼R600初期完全沒有這些設計的原因,這樣一來它只能執行性質和pixel shader很像的GPGPU program,但是繪圖上其實是沒有問題的。(會慢的原因是因為unit數量天生就比較少,這點從RV770的成長曲線就看得出來)
> 是舉例罷了,將來api的的配合下,實現高級別的OOO,提高整體效率.
我不知道為什麼這樣會比較快….
>難道說是,硬件上已經性能過硬? 你擔心的是制造成本與難度, 以及軟體上問題. 除了那些問題, 應該還有頻寬的問題.
>ring bus太擁擠了. 單向的情況下, 是512bit, 如果是半速的, 那就是16個核心分用32Byte*1G=64GB/cycle的頻寬.
>memory與L2之間傳資料要占用ringbus–core訪問memory要占用ringbus, tmu向L2送sample要占用ring bus, L2之間的資料傳輸也要占用ring bus. 應該是很低效.
Larrabee的設計是先研究一個software rasterizer,找出會很慢的部份是哪邊,然後把這些很慢的部份給用硬體實做給加速,只是它的硬體實做是透過CPU….其他廠商則是透過ASIC來實做。
所以其實你前面提到的這些reuse、OOOE都是在想「如何讓繪圖工作高效」這件事情,但是我看起來這些和一個rasterizer的行為其實並不是相符的,畢竟其實rasterizer都是差不多的, software也好hardware也罷。他們既然本來就找了一堆software rasterizer的名家,弄了一個一個演算法出來,那麼他們說這樣的硬體頻寬夠,那應該就是真的足夠。而由於所有的繪圖工作都是經過包含那個software rasterizer的micorOS,那麼行為就應該是和rasterizer無異,其他的ray tracing之類的工作則是以另一個介面去存取Larrabee。
另外,那個ring bus的頻寬有1TB/s,因為一個ring bus有很多段,每段裡面都傳輸不同的資料。
>一般而言, 一個fiber/thread是同一個點只會畫一次, 但是其他fiber或
>thread呢? 有可能會用到同一塊texture,相同U,V位置的sample.
>要從更大的尺度看,例如,非僅僅一個shader,而是多個shader.
重複繪製通常指的是overdraw,但是不是因為UV座標一樣而是因為同pixel,然後z-compare之後認定要reject掉。
上面說了,hardware pipeline不會去分辨相同UV座標的texel「是不是重複」,你說的這些都是software 3D engine面在資料結構上去減少各種不同性能虛耗的範疇,讓硬體設計面去思考這麼多問題,只會被越來越複雜的工作給拖慢。
事實上,thread間通訊是有必要的,但是都是在HPC用途底下,CUDA在這邊花了很多苦心,但是Larrabee這邊的優勢就像你說得很明顯,上面你所提的一些機制在Larrabee上因為是軟體排程,所以要做什麼相對的都很容易。
> 所以問題是: 此類的區域性是否有實際利用價值? 如果有,如何利用呢? larrabee會很困難吧?
> 對于larrabee而言,問題是變為經過過濾的texture,是否有區域性可以利用?
> 對于GPU而言, 問題是變為sample是否有區域性可以利用? 顯然沒有.
我現在不知道對繪圖而言reuse有什麼好處?
> 關鍵是送到以后, 說的極端點,是把全部(上千個)sample都能存儲到L2里> 面, 全部的sample結果可以同時存在. 而GPU是如何呢? shader的寄存> 器是有限的, 能同時存儲? 可能是FIFO里面還能有幾個sample吧?
GT200有64KB, G8x/G9x還是有32KB,R600系列也有256KB的register file,沒有小道哪去啊。
同時存儲?你也沒辦法把cache的所有內容同時取得、同時修改吧。
目前看來Larrabee也是靠cache控制指令,來使得部份的cache空間可以當成scratchpad memory來使用,比方說GT200的每個SM具有64KB的register file,最大則有32warp,所以代表的其實是可以以2KB為單位來作存取。如果在cache上要實現這種控制,只要實做cache line lock就可以了,每次lock個1~2KB(太小的話cache line,這樣就不會被同步機制給交換出去,反過來說就可以看成Larrabee有更多個warp。
但是這都是和thread interconnections沒有關係的,繪圖上是不會用到這些設計,所以這也是為什麼R600初期完全沒有這些設計的原因,這樣一來它只能執行性質和pixel shader很像的GPGPU program,但是繪圖上其實是沒有問題的。(會慢的原因是因為unit數量天生就比較少,這點從RV770的成長曲線就看得出來)
> 是舉例罷了,將來api的的配合下,實現高級別的OOO,提高整體效率.
我不知道為什麼這樣會比較快….
>難道說是,硬件上已經性能過硬? 你擔心的是制造成本與難度, 以及軟體上問題. 除了那些問題, 應該還有頻寬的問題.
>ring bus太擁擠了. 單向的情況下, 是512bit, 如果是半速的, 那就是16個核心分用32Byte*1G=64GB/cycle的頻寬.
>memory與L2之間傳資料要占用ringbus–core訪問memory要占用ringbus, tmu向L2送sample要占用ring bus, L2之間的資料傳輸也要占用ring bus. 應該是很低效.
Larrabee的設計是先研究一個software rasterizer,找出會很慢的部份是哪邊,然後把這些很慢的部份給用硬體實做給加速,只是它的硬體實做是透過CPU….其他廠商則是透過ASIC來實做。
所以其實你前面提到的這些reuse、OOOE都是在想「如何讓繪圖工作高效」這件事情,但是我看起來這些和一個rasterizer的行為其實並不是相符的,畢竟其實rasterizer都是差不多的, software也好hardware也罷。他們既然本來就找了一堆software rasterizer的名家,弄了一個一個演算法出來,那麼他們說這樣的硬體頻寬夠,那應該就是真的足夠。而由於所有的繪圖工作都是經過包含那個software rasterizer的micorOS,那麼行為就應該是和rasterizer無異,其他的ray tracing之類的工作則是以另一個介面去存取Larrabee。
另外,那個ring bus的頻寬有1TB/s,因為一個ring bus有很多段,每段裡面都傳輸不同的資料。
>GT200有64KB, G8x/G9x還是有32KB,R600系列也有256KB的register file,沒有小道哪去啊。
哪有這么大? 是接收sample的寄存器, 而90%的寄存器都是裝運算資料或其他用途.
larrabee可以同時存儲很多sample,便于shader隨到隨用. reuse是很難實現了, 但是相當于一個超大FIFO.
>同時存儲?你也沒辦法把cache的所有內容同時取得、同時修改吧。
關鍵是送到以后,那就是有一定優勢了. 而且cache的帶寬比較大.
還是tmu延遲吸收是關鍵因素? 應該是看場合, 要是可以一次傳很多sample的話? tmu延遲吸收對larrabee就沒有太大影響了.
有的場合,要是傳一點sample頻繁次數卻很多, larrabee就要低效很多了.
thread太低效了,吸收延遲的效率要差太遠了.
>GT200有64KB, G8x/G9x還是有32KB,R600系列也有256KB的register file,沒有小道哪去啊。
哪有這么大? 是接收sample的寄存器, 而90%的寄存器都是裝運算資料或其他用途.
larrabee可以同時存儲很多sample,便于shader隨到隨用. reuse是很難實現了, 但是相當于一個超大FIFO.
>同時存儲?你也沒辦法把cache的所有內容同時取得、同時修改吧。
關鍵是送到以后,那就是有一定優勢了. 而且cache的帶寬比較大.
還是tmu延遲吸收是關鍵因素? 應該是看場合, 要是可以一次傳很多sample的話? tmu延遲吸收對larrabee就沒有太大影響了.
有的場合,要是傳一點sample頻繁次數卻很多, larrabee就要低效很多了.
thread太低效了,吸收延遲的效率要差太遠了.
>哪有這么大? 是接收sample的寄存器, 而90%的寄存器都是裝運算資料或其他用途.
>larrabee可以同時存儲很多sample,便于shader隨到隨用. reuse是很難實現了, 但是相當于一個超大FIFO.
就是有那麼大…. = =)a
那些register file本來就是stage儲存,你取來sample之後要怎麼存都是你的事情啊。
>關鍵是送到以后,那就是有一定優勢了. 而且cache的帶寬比較大.
我覺得沒差…._A_
它只是有把cache的頻寬寫出來,register file的頻寬也可以很大的。
我只是覺得說一邊是少數ALU + cache交換、一個是register file內的蜂巢結構,要比較的話很有得比而已。
>還是tmu延遲吸收是關鍵因素? 應該是看場合, 要是可以一次傳很多sample的話? tmu延遲吸收對larrabee就沒有太大影響了.
上面說過了,TMU不負責延遲吸收。
>有的場合,要是傳一點sample頻繁次數卻很多, larrabee就要低效很多了.
>thread太低效了,吸收延遲的效率要差太遠了.
不要把GPU的方式和Larrabee的軟體排程混為一談,然後說”Larrabee沒有什麼所以一定blah blah”….
—-
抱歉我寫不下去了,暫時無視…. = =)a
>>texture相同,U,V也相同, sample就相同的假設,是>>否就難以成立了呢? 請教一下.
如果模型本身拉遠拉近或縮放或旋轉.
雖然shader演算法不變,貼圖也是同一張.
但是你卻沒辦法共用那些filter texcolor了.
你原本想法類似要畫1百張素描,
但是視點和物體相同,所以想要畫好一張,
其它用影印copy的.對吧?
但是如果另外99張可能要求旋轉角度,畫小張一點,大張
一點…….
雖然視角不變,卻沒辦法用copy的方式.
>>texture相同,U,V也相同, sample就相同的假設,是>>否就難以成立了呢? 請教一下.
如果模型本身拉遠拉近或縮放或旋轉.
雖然shader演算法不變,貼圖也是同一張.
但是你卻沒辦法共用那些filter texcolor了.
你原本想法類似要畫1百張素描,
但是視點和物體相同,所以想要畫好一張,
其它用影印copy的.對吧?
但是如果另外99張可能要求旋轉角度,畫小張一點,大張
一點…….
雖然視角不變,卻沒辦法用copy的方式.