れぽうPのレスから見ると、たぶんある程度の日本からの巡回がいますと思う。(一人くらい?XD)
だから「日本語ヘタですが日記をある程度日本語にする」の考えも出てきます。日本語練習のためにもなるから。
もし日本の方々がいらっしゃれば、日本語でも大丈夫ですから気軽に書き込んでください。
自分以外でも、この日記を見る人は多分「日本語でおk」の人が多いんですw
—-
http://staff.aist.go.jp/t.nakano/VocaListener/index-j.html
VocaListener: ユーザ歌唱を真似る歌声合成パラメータを自動推定するシステム
これはおそらく現時点で得られる最高の参考データである。
もっといいのはプログラム本体とソースですが、それはさすがに無理であろうXD
MikuMikuVoiceどの差は当然、調教パラメータの自動生成(ぼかりすの音節は自動判別、MMVは人による入力)ですが,MMVのほうは多分MMDと同じく、開発工数を減るのは目的ですから。
でもMMVはまだピッチの推定精度をあげる余地があるのようです。 (波形データはまだエイリアシングがありますから)
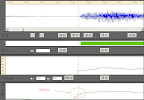
これはある程度に聴感を影響するかもしれない。
(ptt(台湾のBBS)のボカロスレの人に「なんか初音さん十年くらい年取りました」と言われましたw )
生成波形にオーバーサンプルにすることで改善できるかもしれないだから,後に樋口さんのにっやほん日記にフィーバックしてみたいかも。
でも、すでにかなり数の先行者が出てきます:
http://www.nicovideo.jp/tag/MikuMikuVoice
やっばみんながんばりますね。
ツールの刺激效果覿面です。
まだ修正が必要かもしれないんですが、いつ出るか分からないぼかりすより、もう出てきましたMMVの方では、みんなをサポートになることは明白です。
「いまそこにあるぼかりす」(by 松尾さん)の言い方も頷ける。
でも、樋口さん5/28日記のレスによるとマルチパスのやり方も考えてる模様:
1.最初はDynの値を設定せずにVsqで吐き出して、ボーカロイドの喋らせる
2・そのWaveを再びMikuMikuVoiceに戻す
3.戻したWaveと元のWaveからDynを計算する…
「面倒臭い上に、これで上手くいくという保障もなさそう…」と言いました樋口さんでしたが、でもこれはまさしくぼかりすのやり方です。XD
正確的には、DYNを0~127まで与えられて合成する、そしてオリジナル(人間が歌うのデータ)との波形距離を最小限します。
その上でさらに多数回の実行を行い、四回反復でパラメータ推定する。
それはVocaloidの仕様によるへんな減衰にされたことを計算で回避するのためだけど、マルチパスの考え方は「ぼかりす」のやり方に同じです。
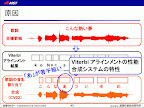
ぼかりすもこのやり方で減衰を回避したことのようです。(「Viterbi アラインメント (HMM)性能合成システムの特性」,発表資料page 43)
つまり、マルチパスのやり方で減衰特性を計算しだ上でのパラメータを生成しましたのがぼかりすです。
VSTiのサポートもそのため。MMVの延長線の上にはぼかりすが存在するかもしれない。
一周間やるだけでこれくらいのことを思いついた樋口さん、さすがに「ニコニコ開発局長」に呼ばれる人です。
凄すぎ。(そしてこれくらいのツールを「なんちゃってツール」で無料配信することの懐の深さもさすがです)
でもこれじゃマルチパスは特許の関係で実装できませんかもしれない。
これは「ぼかりすはMMVと同じくらいのことしかやってません」ではなく、
MMVをボカロユーサーに広く使わせる有効なツールになるために、ソフトのシステム要求を最小限にする樋口さんの判断の正確さを評価するです。
ぼかりすは歌詞さえ知れば(オリジナル曲とカヴァー曲も同じく)、完全自動で分析、そしてある程度(サンプルは3~5回くらい?)の錯誤を手動で訂正さえすれば、自動的調教を行います。
そして調教のデータはボーカロイドと本来の歌い手共に有效です。これくらい高度の機能を一度行うシステムはさすがに大規模になります。http://d.hatena.ne.jp/grgr56/20080430
「ぼかりす」について今の時点でわかっている事「素人を喜ばせる」観点から書く。
- 結局「元歌を人間が上手に歌ったデータ」がなくては使えないものなのか?
- 「人間の上手な歌唱」から抽出されたパラメータは、オリジナル歌唱著作権の中にあるのか?
これらは「素人が喜ぶかどうか」に大きく関わってくる事柄だ。この二つの質問に対する答えがNoであればそれは「神調教ツール」。公開されれば影響は計り知れない。
ここにも指摘したのように、「元歌を人間が上手に歌ったデータ」の必要はありません。ぼかりすは歌下手の人のデータ自体にも調教を行いますから。
パラメータを抽出されたことを制限しなければ、「神調教ツール」おそらくマジになります。
—-
論文によると、ぼかりすはマルチパスの分析が必要ですから、かなりのシステムスペックが要りますかもしれないだが,そのくらいの価値は絶対あります。
なぜかと言うとVocaListener-plusです。 VocaListener-plusは音高変更とスタイル変更機能がついています、つまり様々の歌手の歌唱スタイルの数值化が可能です。
おそらくほかのソフトの補助が必要かもしれないんだが、それでも「なんちゃって若本(?)」とかのマネ事が自動的データベース化できますから。
http://blogs.itmedia.co.jp/closebox/2008/06/post-84e9.html
「ぼかりす」で知った、プロとアマの違い
すでに松尾さんの指摘通り、プロとアマの違いがわかります、それはアマをプロにすることに繫ぎますから。
「すでに故人になった」の方の歌唱力の再現も可能になります。さらに微妙の音楽ノウハウを数值化、データベースにすることで音楽教育の向上をさらにサポートすることが出来るかもしれない。
「音楽を理解するコンピュータの実現に向けて ~ リアルタイム音楽情景記述システムの構築 ~ 」のように、音楽を理解するコンピュータの出来上がりです。
彼女との付き合いはもうMIDIデータ流れではなく、「とう歌えばいいか」ということになる。
これは【初音ミク】鍵盤ハーモニカ【少女】の音楽教育の理想形のひとつかもしれないたと思う。
現状ですら、作曲経験がなく楽器経験すらない方までソフトを購入しており、恐らくはほんの一握りでしょうが、それをきっかけにこれから音楽を本格的に始めてみようと思った方も中にはいらっしゃると思うんです。
そんなこれまでの常識を覆すような初音ミクがもし実体を持つことになったら、起こる奇跡は生半可なモノじゃないと思うんですね。
(来世さんより)
この10が月の出来事が思うと、「初音ミクの奇跡は続きます」だと信じたい。
——————————————————————————————————————————————————————————–
看到れぽうP的發言,想說說不定這邊還有日本的人在巡迴….XD
開始想寫日文和中文雙解的東西。雖然日文程度實在是很爛啦_A_||||||
總之希望日本的朋友們可以輕鬆地以日文發言,反正會看這邊的人大概看得懂的比例比較高。XD
以下是上面這篇本來想寫的中文版,寫的時候並不是中文一句日文一句,而是”以想表達的東西”來思考。
所以直接翻的話可能會很爆炸XD
—-
http://staff.aist.go.jp/t.nakano/VocaListener/index-j.html
VocaListener: ユーザ歌唱を真似る歌声合成パラメータを自動推定するシステム
完整的論文、發表資料PDF…. 這個只能說夫復何求。XD
理所當然地,MMV為了節省開發時間,把音節推測交給實際操作的人來處理,並且將介面盡可能簡化這點,可以看出樋口老師的作風;但是在ptt Vocaloid版分享的結果,似乎波形部分的精確度還有努力的空間。(把畫面放大可以看到明顯帶有鋸齒的波形)
這應該會對聽感有點影響。
ptt的某K兄說道:「pitch隨時間變化的間距太長,所以造成轉出來的曲線不夠平滑,打開轉好的VSQ來看就知道」「聽起來聲音有點….初音老了十歲的感覺(炸)」
不過即使如此,工具扔出來就是會刺激很多人上來try。
http://www.nicovideo.jp/tag/MikuMikuVoice
而且不乏優秀的東西,昨天的兩首原創曲就是典型。
工具會帶來突破就是指這種狀況吧。
話說由於先前WX5檢證的關係,自己也在嘗試拿MMV來做cover,不過實在是對自己的素人程度極為絕望XD
但是可以知道不管還需不需要(或者打不打算)更正,比起還不知道什麼時候推出的VocaListener,絕對是已經推出的MMV會帶來的生產力比較高。
所謂「いまそこにあるぼかりす」的說法的確會讓人很有共鳴。
不過為了先前已知的不明衰減問題,在5/28日記的回文裡面,樋口大先生也考慮過multi-pass的做法:
1.最初はDynの値を設定せずにVsqで吐き出して、ボーカロイドの喋らせる
2・そのWaveを再びMikuMikuVoiceに戻す
3.戻したWaveと元のWaveからDynを計算する…
雖然當天看到速報就已經開始覺得是,但是今天論文出來發現這真的就是ぼかりす的作法實在是讓人噴了。
實際上就是先以0~127的參數作多次合成來做比較,甚至還執行四次來推定資料。
所以也就是說雖然樋口大先生因為懶與未定性所以沒做,實際上思考本身是完全正確的。
由於「Viterbi アラインメント (HMM)性能合成システムの特性」一文的敘述可以知道,這指的應該是採用音節切割合成法的Vocaloid實際的特性,也就是說ぼかりす確實是以這個方式來迴避音節的衰減問題。
(也因為這個樣子,為了多次生成,ぼかりす必須要繞過Vocaloid Editor來做多次合成,這也是ぼかりす支援VSTi的目的)
第一次碰MIDI規格,一個禮拜下來就可以想到這些東西的樋口大先生實在是很強大。XD
(然後把這些東西當成「なんちゃってツール」直接扔出來的胸襟也實在很猛)
不過既然已經是專利了,那大概永遠都沒辦法做上去。
VocaListener可以透過先得知歌詞內容的方式,自動將歌詞填進音節內。這點非常強大….
這並不是在說VocaListener的實作和MMV同級,要達成VocaListener的程度鐵定需要極為大量的know-how。
從VocaListener的實作規模也可以看出,當時樋口老師認定應該放棄十分明智。http://d.hatena.ne.jp/grgr56/20080430
「ぼかりす」について今の時点でわかっている事「素人を喜ばせる」観点から書く。
- 結局「元歌を人間が上手に歌ったデータ」がなくては使えないものなのか?
- 「人間の上手な歌唱」から抽出されたパラメータは、オリジナル歌唱著作権の中にあるのか?
これらは「素人が喜ぶかどうか」に大きく関わってくる事柄だ。この二つの質問に対する答えがNoであればそれは「神調教ツール」。公開されれば影響は計り知れない。
由於連唱得不好的user資料也會在mult-pass內受到調教,所以並不需要「唱得很好的原始資料」
也就是說只要法律不限制抽取唱法參數的行為,「神調教ツール」絕非誑語。
此外,由於multi-pass和多聲道生成的交叉比對,ぼかりす鐵定會需要非常大的硬體資源。
但是由於有VocaListener-Plus,具備音高變更與歌唱類型變更的功能,我相信它確實具備了先前期望過的「歌唱參數數據化」的能力。
http://blogs.itmedia.co.jp/closebox/2008/06/post-84e9.html
「ぼかりす」で知った、プロとアマの違い
和松尾先生講的一樣,你可以透過數值化來得知和專業人士的差距,就代表說這有辦法讓你知道專業人士怎麼唱,和你的差別在哪邊。
進一步地來說,也可以把已經作古的歌手唱法給數值化,這些微妙的know-how能夠加以統計起來,形成資料庫的話,絕對會對音樂教育產生極大的助益。
就像「音楽を理解するコンピュータの実現に向けて ~ リアルタイム音楽情景記述システムの構築 ~ 」這篇提到的一樣,讓電腦可以”理解音樂”。
妳可以不必再碰底層的MIDI編輯、而是實際”教她該怎麼唱歌”。
這其實就是【初音ミク】鍵盤ハーモニカ【少女】所指出的,音樂教育的一種理想型才對。
現状ですら、作曲経験がなく楽器経験すらない方までソフトを購入しており、恐らくはほんの一握りでしょうが、それをきっかけにこれから音楽を本格的に始めてみようと思った方も中にはいらっしゃると思うんです。
そんなこれまでの常識を覆すような初音ミクがもし実体を持つことになったら、起こる奇跡は生半可なモノじゃないと思うんですね。
( 来世 さんより)
回想起這不過是十個月以來的改變,就會讓人相信,ミク的奇蹟還會繼續下去。
—-
以下巡迴
http://d.hatena.ne.jp/beentocanaan/20080529
[音楽周辺][ニコニコ動画] Vocaloidは、すでに人間に追いついた。
http://d.hatena.ne.jp/mame-tanuki/20080601/p2
ボーカロイドの進化に絶望した~絶望のニコ動シリーズ~
http://zh.wikipedia.org/wiki/VocaListener
中文版VocaListener資料,香港的朋友所整理。
式子引用自論文原文。
http://akira-izumi.cocolog-nifty.com/patent/2008/06/post_c0a5.html
ぼかんないんです><技法の解析
http://akira-izumi.cocolog-nifty.com/patent/2008/06/post_878b.html
機械的イフェクトによるビブラート
即使沒有V-Vocal可用,同時期應該也有別的東西可以實作類似功能才是,比方說Auto-Tune。
Auto-Tune由於有real-time校正,連現場演唱都派得上用場….此外,V-Vocal也有Pitch to MIDI功能。
http://www.nicovideo.jp/thumb/sm3478357
「TからSへ」時就已經很喜歡這種調調了,這回更棒啦。